Blog
Operator-grade essays on harness engineering, context packs, replay, evaluators, and running agents in production.
Get new posts by email
ContextOS essays, field notes, and implementation guides.
Start with the path that matches your job
The best ContextOS essays are built as field guides: pick the role path, then go deeper through the series.
For engineering leaders
Architecture, harness quality, runtime boundaries, and the build path from prototype to governed agent.
For product managers
How to turn agent ideas into intents, launch gates, scorecards, trust surfaces, and operating loops.
For executives and operators
Plain-English mental models for authority, scorecards, approvals, and feedback after launch.
For security and compliance
Identity, prompt-injection boundaries, approval tiers, replay, and audit controls for high-authority agents.
The essays most worth sharing first
Red-Team Agent Hijacking: Build a Security Eval Gate for Repeat Attacks
A practical agent-hijacking evaluation harness: scenario design, adaptive and repeated attempts, path-aware metrics, deterministic release gates, and production replay.
If you are new, start here
Start here
If you have read nothing yet, read these in order.

Agentic AI Systems Before and After ContextOS
A table-first guide to why agentic systems need bounded context, governed tools, typed decisions, replay, evaluation, and controlled improvement.

The Agent Harness Audit: A Production Readiness Checklist for Governed AI Agents
A production readiness audit for agent harnesses: forty-four runtime controls grouped into eight evidence-backed outcomes.
AGENTS.md Done Right: The Navigation File That Actually Helps Coding Agents
How to write AGENTS.md as a short, scoped, testable navigation file for coding agents instead of a bloated prompt dump.

End-to-End Refund: How 12 Primitives Compose in One Production Run
A single refund run traced through 12 ContextOS primitives, from invokeAgent envelope to byte-equal replay.
AI literacy series
Mental models for business leaders, domain experts, and operators learning how to think about real agentic systems.

AI Tokenomics: From Cost per Token to Cost per Trusted Outcome
AI tokenomics connects cost per token, agentic cost multipliers, routing, evals, governance, and cost per trusted outcome.

The Autonomy Budget: How Enterprises Should Decide What AI Agents Are Allowed to Do
A practical governance model for granting AI agents bounded authority based on risk, evidence, policy confidence, evals, and approval.

AI Agents for Business Leaders: Build the Airport, Not Just the Plane
A practical executive playbook for agentic AI: define the work, evidence, authority, scorecards, approvals, security, observability, and improvement loop.
Before Your Team Asks for an AI Agent, Map the Real Work
A practical guide for business teams mapping real work before building agents: actors, evidence, tools, decisions, risks, exceptions, and feedback loops.
Trusting AI at Work: Approvals, Boundaries, and Receipts
A plain-English guide to agent trust: what AI can read, draft, send, change, approve, and how receipts make decisions accountable.
How to Judge AI Work: Scorecards, Not Vibes
A practical guide for business teams evaluating AI agents with scorecards, examples, traces, human corrections, and launch gates instead of demos and vibes.
AI Does Not Launch Once: Feedback Loops After Go-Live
A plain-English guide to operating agents after launch: corrections, recurring failures, proposal queues, rollout, rollback, and review.
Product management series
How product managers shape real agentic systems with intents, authority, scorecards, rollout gates, and improvement loops.

Product Managers: How to Think About and Build Complex Agentic Systems
A practical PM guide to building agentic systems with workflow maps, intents, context packs, tools, records, evals, and rollout gates.
From PRD to Intent Catalog: The PM Spec for Agentic Products
How PMs turn vague agent ideas into intent catalogs, task templates, authority models, DecisionRecords, and launch criteria.
The Control Tower Pattern: How PMs Should Design Multi-Agent Products
A PM guide to splitting multi-agent systems into specialist lanes while keeping orchestration governed and inspectable.
Scorecards Before Screens: Evals and Launch Gates for PMs Building Agents
A PM guide to defining agent quality with datasets, trace reviews, scorecards, release gates, and business metrics before building the agent UI.
Trust Is a Product Surface: Approval Modes and Human Control for Agentic Products
How PMs should design trust for real agentic products: approval modes, human roles, evidence snapshots, DecisionRecords, policy gates, and graceful failure.
Operating Agent Products: Feedback, Rollout, and the Improvement Loop
A PM operating model for shipped agents: trace review, corrections, proposal queues, scorecards, rollout, and rollback.
Agent engineering series
How strong AI engineers build agents with datasets, scorecards, traces, and harness improvement loops.
How to Develop an Agent with an Agent Harness, End to End
An end-to-end field guide for building agents as measurable harnesses: context, planning, tools, records, evals, rollout, and learning.

How Great AI Engineers Build Agents: Datasets, Scores, and Harnesses That Improve
Why strong AI engineers build datasets, scorecards, traces, and improvement loops instead of treating agents as prompts plus tools.
Dataset-First Agent Engineering: The Golden Sets Behind Reliable Agents
A practical guide to golden sets, task distributions, corrected runs, held-out releases, and production slices for agent engineering.
Scorecards Over Vibes: The Five Metrics That Keep Agents Honest
The five metrics that keep agents honest: policy, utility, latency, safety, and economics.
Trace Review Is the Agent Debugger: Grade the Path, Not Just the Answer
How trace review grades the path, not just the answer, by inspecting context, plans, tools, guardrails, critic verdicts, and corrections.
Harness Candidates Are Model Checkpoints: How to Improve Agents Without Silent Mutation
How to treat every prompt, retrieval, tool, policy, and evaluator change as a scored, reviewed, reversible harness candidate.
Agent security engineering series
Threat-model, contain, authorize, and red-team tool-using agents with deterministic controls around the model.
Threat-Model an AI Agent: Sources, Sinks, Authority, and Blast Radius
A practical AI agent threat-modeling method that maps untrusted sources to dangerous sinks, then constrains identity, authority, data, and blast radius at deterministic runtime boundaries.
Prompt Injection Is a Boundary Problem, Not a Prompt Problem
Why "smarter prompts" don't defend against indirect prompt injection, and what changes when authority lives outside the model's view.

Agent Identity Is the New Trust Boundary
A practical model for separating agent identity, workload proof, user delegation, scoped authority, and audit across MCP and A2A.
Secure the MCP and Tool Supply Chain: Trust Must Be Continuous
How to secure MCP servers, remote tools, connectors, skills, and their outputs with admission controls, audience-bound authorization, least privilege, runtime containment, and revocation.
Build the Tool Gateway: The Boundary That Actually Stops a Bad Action
A build-along for the Tool Gateway: adapter manifests, typed envelopes, resolver checks, dispatch, and destructive-action boundaries.
Approval Gates in Code: The Destructive-Mode Handshake
A build-along for approval gates: frozen evidence, human signatures, gateway redemption, and replayable destructive-action handshakes.
Red-Team Agent Hijacking: Build a Security Eval Gate for Repeat Attacks
A practical agent-hijacking evaluation harness: scenario design, adaptive and repeated attempts, path-aware metrics, deterministic release gates, and production replay.
Architecture & foundations
The five planes, why prompts alone do not scale, what context engineering means.

The State of AI Agents in 2026: Standards Converged, Models Improved, Production Moved to the Harness
A mid-2026 review of agentic AI: MCP, A2A and AP2 converged as standards and models got more reliable — yet the bottleneck moved to the governed agent harness.

SecondBrain: A Local-First Agent Operating System You Can Run, Inspect, and Trust
SecondBrain is an open-source, local-first agent OS: cognition, memory, governed tools, durable sessions, workflows, and bounded self-improvement in one inspectable runtime you run on your own machine. Here is how it works and how to run it.
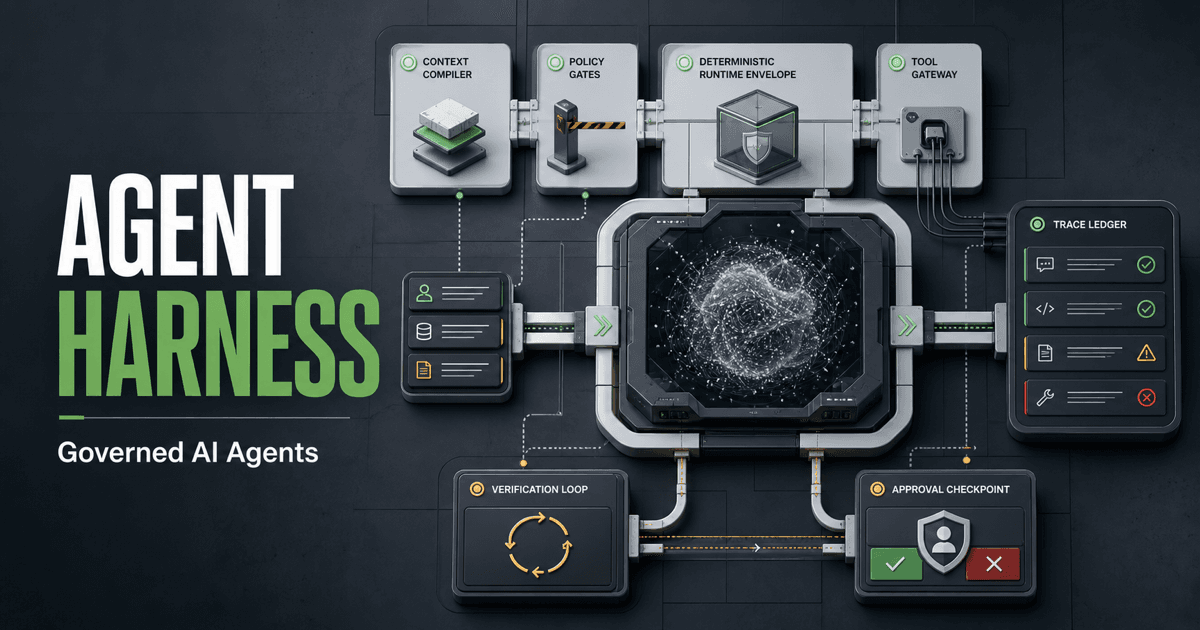
Agent Harness: An Architectural Framework for Production AI Agents
A whitepaper on typed contracts, policy gates, traces, verification loops, and release control for production AI agents.
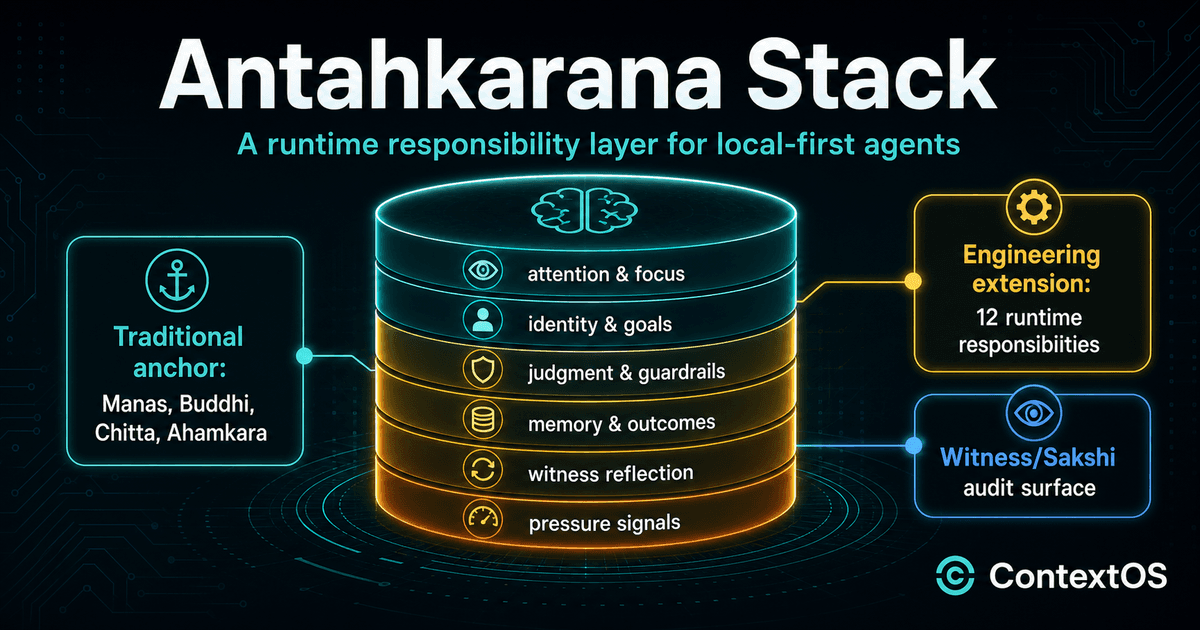
Antahkarana Stack: A Cognitive Layer for Local-First Agents
A builder-facing explanation of Antahkarana as an engineering layer inspired by the inner faculties of Manas, Buddhi, Chitta, and Ahamkara.
The Five Planes of Agentic Operating Systems
A working decomposition for production agent systems: Intelligence, Context, Decision, Action, and Trust.

ContextOS: A Research-Grounded Architecture for Governed Agent Runtimes
A research-grounded framing of ContextOS as a governed runtime for context, tools, memory, security, evaluation, replay, and optimization.
Beyond Prompts: The Architecture of Trust for Agentic AI
Building a governed decision runtime across Intelligence, Context, Decision, Action, and Trust — with evaluator scoring, approval tiers, and replay-bound audit.
Context Engineering in Production
Why most agent failures are not model failures — they are context failures — and what changes when context becomes a versioned, testable, replayable contract.
Context Packs in Practice: From Spec to Run
A practical walkthrough of Context Packs: buckets, policy bundles, evaluation gates, lifecycle, and the compile pipeline.
Building the runtime
Compile, gateway, Critic, evaluators, failure handling — the per-request pipeline.
Build the Context Pack Compiler: Eight Stages, Eight Files
A build-along for the Context Pack compiler: eight deterministic stages that turn runtime inputs into a typed compiled context.
AI Gateway and LLM Router: Model Choice Is a Runtime Decision
How an AI Gateway and LLM Router make model choice policy-bound, budgeted, observable, and replayable across production agent workflows.
MCP Adapters in Production: The Manifest Is the Safety Boundary
How MCP fits behind a production adapter manifest with schemas, auth, approval modes, idempotency, observability, and replay.
The Critic: verify, score, consolidate — in 80 Lines
A compact Critic implementation that verifies plans, scores outcomes, consolidates results, and records caveats.
Wiring the Five Evaluators: Policy, Utility, Latency, Safety, Cost
A build-along for wiring policy, utility, latency, safety, and cost evaluators into a release-gated scorecard.
Failure Playbooks: The Typed Verdict Map
How to replace generic retry loops with typed failure verdicts, compensations, escalation paths, and reversal-token checks.
Trust, audit, governance
Replay, approval modes, approval-gate handshakes, and the security boundary.
Replay Is the Real Audit Log
Why "we have logs" is not an audit story, and what a hash-chained Decision Record plus canonical replay actually buys you when an incident hits.
Replay Harness in Code: Reproducing a DecisionRecord Byte-for-Byte
A TypeScript build-along for replay: input loading, hash-chain verification, canonical loop replay, and DecisionRecord diffing.
Approval-Mode Tiers: A Risk Taxonomy You Can Actually Ship
Why ad-hoc approval gates rot in production, and how five canonical risk tiers turn governance from a meeting into a contract.

Reversibility Is the Missing Safety Primitive for AI Agents
Prevention decides whether agents may act. Reversibility lets them survive being wrong through reversal contracts, compensation, and blast-radius caps.
Memory & evidence
How agents remember, what gets promoted, how knowledge is grounded.

AI Agent Memory Is Broken: Designing Multi-Layer Memory for Production AI Agents
A production guide to AI agent memory architecture: designing long-term memory for AI agents across working, episodic, semantic, procedural, and organizational layers. Why RAG is not memory, why vector databases are not memory, and how governed, situation-aware memory prevents memory poisoning in enterprise AI agents.

Give Claude Code, Cursor, and Codex Persistent, Auditable Memory
Coding agents are brilliant and amnesiac. SecondBrain's open-source Memory API gives Claude Code, Cursor, Codex, and ChatGPT shared, local-first memory over HTTP and MCP — where every answer carries a citation back to the source chunk.
The Identity Layer: Agents Need Two Identities, Not One
Why governed agent runs need entity identity, delegated user identity, and workload identity in the same RunContext.
Promotion-Aware Memory: Capture, Review, Promote, Recall in Code
A build-along for agent memory: capture, review, promote, recall, contradiction checks, and governed memory writes.
Context Graphs: Decision Lineage as a System of Record
How hash-chained DecisionRecords turn execution-time context into a queryable lineage graph for why an agent acted.
Enterprise use cases
Concrete agentic workflows for incident response, financial crime, regulated operations, data stewardship, and software delivery.
Agentic Incident Command Center: Agents Can Coordinate, Boundaries Still Decide
How incident-response agents can coordinate signal, diagnosis, remediation, communications, and approvals without bypassing operational boundaries.
Financial Crime Operations: Agentic AI Needs Evidence, Not Autonomy
How KYC, AML, sanctions, and fraud casework can use agentic workflows while preserving evidence, policy gates, and human adjudication.

The AI Software Delivery Squad: From Ticket to Proof-Carrying Pull Request
A production blueprint for coding agents that scope, patch, test, review, and open pull requests without inheriting merge or deploy authority.
Reviewers & improvement
Reviewer agents, rollouts, operator corrections becoming versioned StrategyRules.
Harness Improvement Loops Need Replayable Environments
Why harness improvement needs replayable episodes, bounded mutations, scorecards, source closure, and promotion gates.
Autotune the Harness: Baking the Improvement Loop into ContextOS
How ContextOS treats autotune as a gated loop over traces, scorecards, replay sets, bounded candidates, approval, and rollout.
Building a Compliance Reviewer Agent in 60 Lines and a Golden Set
How to build a compliance reviewer agent with a typed verdict envelope, rubric, golden set, and change-control queue.
Building a Reliability Reviewer Agent: 70 Lines Past the Compliance One
How to extend the reviewer pattern for reliability: timeouts, retries, idempotency, fallback behavior, and rollback declarations.
Pack Rollout in Five Stages: Shipping a Context Pack Without Blowing Up Production
A five-stage rollout model for Context Packs: shadow, internal, low-risk, monitored expansion, full release, and rollback.
From Operator Correction to Released StrategyRule: The Improvement Loop, Coded
How one operator correction becomes a reviewed, replayed, versioned StrategyRule that prevents repeat agent failures.