Run AI agents on production systems with replayable decisions.
ContextOS gives teams the harness around the model: compiled task context, enforced policy, governed tool use, validation before completion, and an audit record that can be replayed after the run. It keeps the core promise of agents while making their decisions inspectable, reversible, and improvable.
Audit your agent harness against its own code, or see how one run works and build the Quickstart.
Built for platform, product, and applied AI teams moving agents from prototypes into governed workflows.
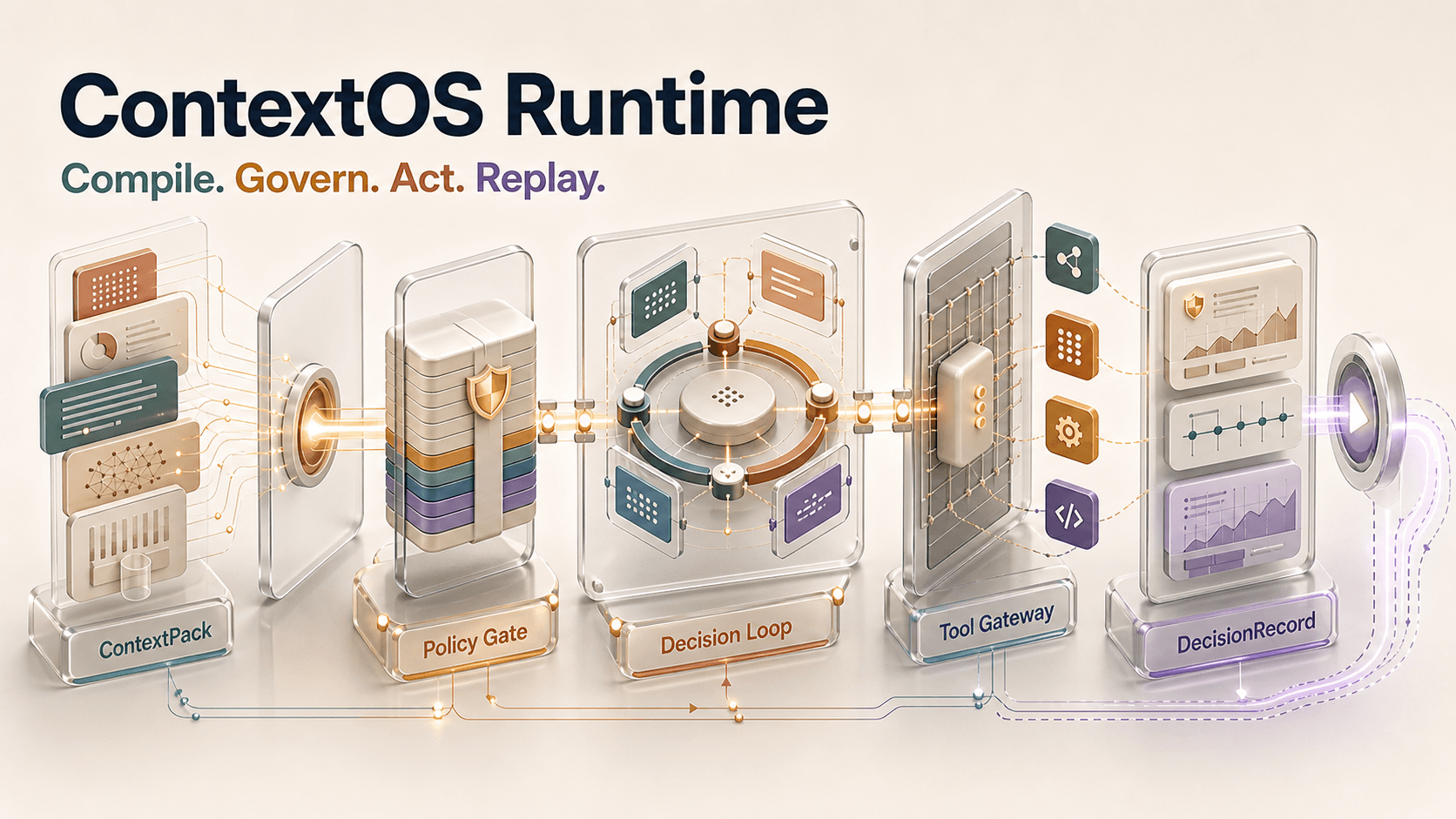
One run moves through a compiled context packet, deterministic policy checks, a bounded decision loop, governed tools, and a replayable record.
- 01Intelligence
Evidence, ontology, memory, and identity handles.
- 02Context
Compile the request into a budgeted ContextPack.
- 03Decision
Plan, execute, and critic-check inside bounds.
- 04Action
Route every external effect through the Tool Gateway.
- 05Trust
Emit policy, approval, trace, replay, and record state.
Compile the right context
Govern the decision loop
Record replayable decisions
Improve without prompt drift
From request to replayable DecisionRecord
A ContextOS run starts as an invokeAgent envelope and exits as a typed DecisionRecord. In between, the harness compiles context, verifies policy, limits tools, scores the output, and records the evidence needed for audit and replay. Long-running work resumes by session_id against pinned pack + snapshot.
Five planes keep agent systems understandable
ContextOS keeps the model inside a larger execution environment. Intelligence stores what the system can know. Context chooses what this request may use. Decision turns context into a bounded plan. Action mediates external effects. Trust governs the other four with policy, evaluation, replay, and improvement.
One signed RunContext across the lifecycle
run_id, trace_id, session_id, tenant_id, user delegation, agent workload identity, safety_mode, and run_budget travel through every contract. Pressure signals flow alongside as Functional State.
Risk is typed before a tool is callable
read_only · local_write · network · delegated · destructive for risk; observe · recall · think_support · act · verify for kind. Together they bound every capability.
One Tool Gateway for every external effect
MCP, A2A, OpenAPI, custom adapters, chat, email, voice, API, webhook, and SMS all use one envelope shape, one policy boundary, and OTEL trace propagation end-to-end.

RunContext crosses Intelligence, Context, Decision, Action, and Trust so one execution vocabulary survives from request to replay.
- 01Intelligence
Stable facts, identity, evidence, and memory.
- 02Context
Per-request compilation and budgeted context.
- 03Decision
Bounded planning, execution, and critique.
- 04Action
Governed tools, adapters, and external effects.
- 05Trust
Policy, audit, replay, and evaluator control.
The operating model behind the runtime
Each plane owns a clear responsibility, with spec docs for interfaces, failure modes, operational concerns, and evaluation metrics. That keeps harness engineering concrete enough for platform teams to build, review, and operate.
Intelligence plane
Context plane
Decision plane
Action plane
Trust plane
Corrections become release-gated harness upgrades
Prompt edits are not an improvement loop. ContextOS turns failed runs, operator corrections, evaluator regressions, and pressure signals into typed proposals. Nothing auto-applies: every proposed change runs through replay, review, and the same promotion path as packs and policies.
Insight Synthesizer
Strategy Compiler
Feedback Store
Chief-of-Staff
Research Queue
Autotune
Governance belongs in the runtime, not in a prompt
Sandbox profiles, consent records, functional state, durable sessions, and tool approvals are typed primitives. They compose with the canonical contract so trust has the same shape across every run, every tenant, and every integration channel.
Sandbox profiles
Typed, signed contracts for code execution. Pinned image, no host mount, no inbound network, hard caps. Bound per capability.
Consent records
First-class, append-only consent gating PII memory promotion at the candidate stage. Revocation honored on next recall.
Functional state
Typed per-turn pressure signals (budget / loop / evidence / gate / conflict) read by the Critic — never by the model.
Background sessions
Hour-scale durable runs with checkpoint after every Critic verdict. Resume by session_id against pinned pack + snapshot.
- MCP, A2A, OpenAPI, custom — one envelope shape; one policy boundary.
- Skills compose capabilities + prompt fragments + their own evaluation suites.
- User delegation + agent workload identity (SPIFFE-style) on every call.
- Semantic discovery — tools resolved from intent, not catalog dumps.
- Cached read-only aliases for prompt density; alias cache invalidated on bundle promotion.
- Idempotency keys, retries, circuit breakers, dead-letter handling.