Read ContextOS by job to be done
ContextOS is easiest to learn through the problem you are trying to solve: govern agents, build the runtime, shape the product, or prove trust.
If you read only one path
Start here for the shortest route from business problem to governed production run.

AI Agents for Business Leaders: Build the Airport, Not Just the Plane
A practical executive playbook for agentic AI: define the work, evidence, authority, scorecards, approvals, security, observability, and improvement loop.

Agentic AI Systems Before and After ContextOS
A table-first guide to why agentic systems need bounded context, governed tools, typed decisions, replay, evaluation, and controlled improvement.

The Agent Harness Audit: A Production Readiness Checklist for Governed AI Agents
A production readiness audit for agent harnesses: forty-four runtime controls grouped into eight evidence-backed outcomes.

End-to-End Refund: How 12 Primitives Compose in One Production Run
A single refund run traced through 12 ContextOS primitives, from invokeAgent envelope to byte-equal replay.
Most useful first shares
Threat-Model an AI Agent: Sources, Sinks, Authority, and Blast Radius
A practical AI agent threat-modeling method that maps untrusted sources to dangerous sinks, then constrains identity, authority, data, and blast radius at deterministic runtime boundaries.
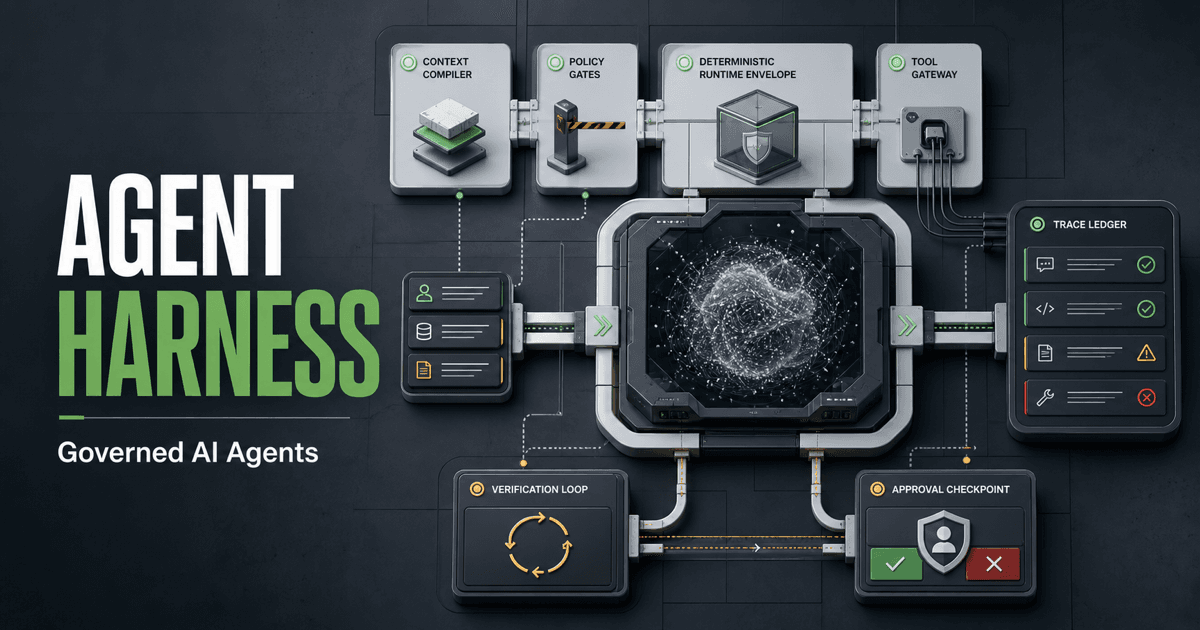
Agent Harness: An Architectural Framework for Production AI Agents
A whitepaper on typed contracts, policy gates, traces, verification loops, and release control for production AI agents.

Agent Identity Is the New Trust Boundary
A practical model for separating agent identity, workload proof, user delegation, scoped authority, and audit across MCP and A2A.
The Agent Harness Audit: A Production Readiness Checklist for Governed AI Agents
A production readiness audit for agent harnesses: forty-four runtime controls grouped into eight evidence-backed outcomes.
For engineering leaders
Architecture, harness quality, runtime boundaries, and the build path from prototype to governed agent.

ContextOS: A Research-Grounded Architecture for Governed Agent Runtimes
A research-grounded framing of ContextOS as a governed runtime for context, tools, memory, security, evaluation, replay, and optimization.

How Great AI Engineers Build Agents: Datasets, Scores, and Harnesses That Improve
Why strong AI engineers build datasets, scorecards, traces, and improvement loops instead of treating agents as prompts plus tools.
Build the Tool Gateway: The Boundary That Actually Stops a Bad Action
A build-along for the Tool Gateway: adapter manifests, typed envelopes, resolver checks, dispatch, and destructive-action boundaries.
Replay Harness in Code: Reproducing a DecisionRecord Byte-for-Byte
A TypeScript build-along for replay: input loading, hash-chain verification, canonical loop replay, and DecisionRecord diffing.
For product managers
How to turn agent ideas into intents, launch gates, scorecards, trust surfaces, and operating loops.

Product Managers: How to Think About and Build Complex Agentic Systems
A practical PM guide to building agentic systems with workflow maps, intents, context packs, tools, records, evals, and rollout gates.
From PRD to Intent Catalog: The PM Spec for Agentic Products
How PMs turn vague agent ideas into intent catalogs, task templates, authority models, DecisionRecords, and launch criteria.
Scorecards Before Screens: Evals and Launch Gates for PMs Building Agents
A PM guide to defining agent quality with datasets, trace reviews, scorecards, release gates, and business metrics before building the agent UI.
Operating Agent Products: Feedback, Rollout, and the Improvement Loop
A PM operating model for shipped agents: trace review, corrections, proposal queues, scorecards, rollout, and rollback.
For executives and operators
Plain-English mental models for authority, scorecards, approvals, and feedback after launch.
AI Agents for Business Leaders: Build the Airport, Not Just the Plane
A practical executive playbook for agentic AI: define the work, evidence, authority, scorecards, approvals, security, observability, and improvement loop.

The Autonomy Budget: How Enterprises Should Decide What AI Agents Are Allowed to Do
A practical governance model for granting AI agents bounded authority based on risk, evidence, policy confidence, evals, and approval.
Trusting AI at Work: Approvals, Boundaries, and Receipts
A plain-English guide to agent trust: what AI can read, draft, send, change, approve, and how receipts make decisions accountable.
AI Does Not Launch Once: Feedback Loops After Go-Live
A plain-English guide to operating agents after launch: corrections, recurring failures, proposal queues, rollout, rollback, and review.
For security and compliance
Identity, prompt-injection boundaries, approval tiers, replay, and audit controls for high-authority agents.
Threat-Model an AI Agent: Sources, Sinks, Authority, and Blast Radius
A practical AI agent threat-modeling method that maps untrusted sources to dangerous sinks, then constrains identity, authority, data, and blast radius at deterministic runtime boundaries.
Agent Identity Is the New Trust Boundary
A practical model for separating agent identity, workload proof, user delegation, scoped authority, and audit across MCP and A2A.
Secure the MCP and Tool Supply Chain: Trust Must Be Continuous
How to secure MCP servers, remote tools, connectors, skills, and their outputs with admission controls, audience-bound authorization, least privilege, runtime containment, and revocation.
Red-Team Agent Hijacking: Build a Security Eval Gate for Repeat Attacks
A practical agent-hijacking evaluation harness: scenario design, adaptive and repeated attempts, path-aware metrics, deterministic release gates, and production replay.