TL;DR
Most production agent failures are not pure model failures. They are harness failures: missing task contracts, overbroad context, unsafe tool exposure, weak policy gates, absent observation checks, invisible memory writes, and no replayable trace.
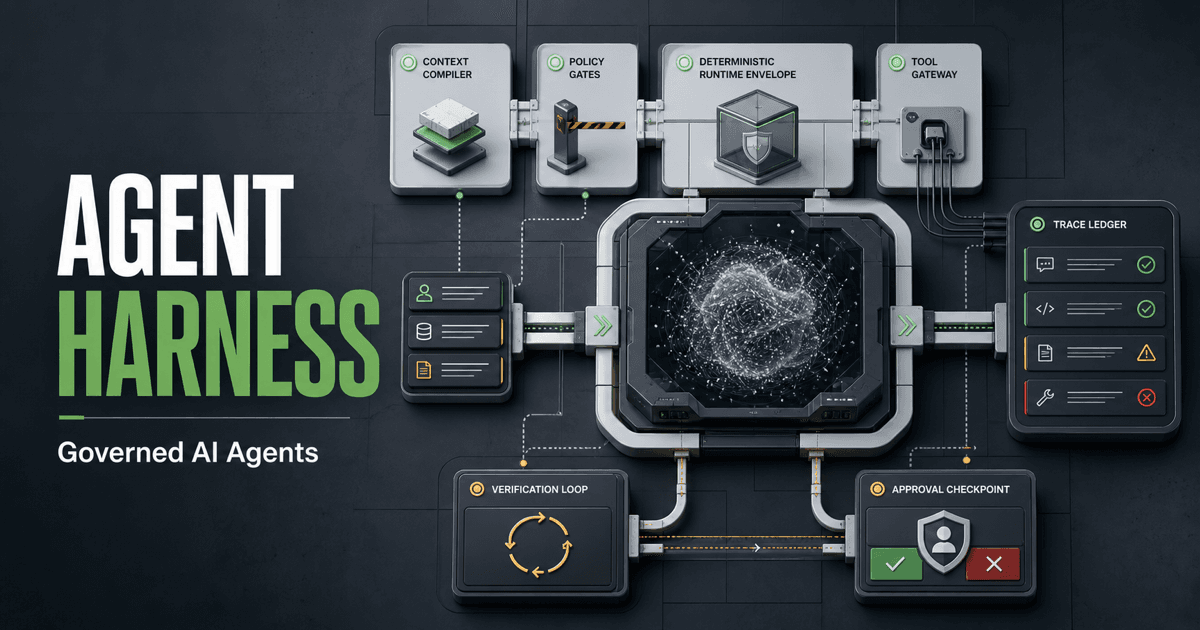
An Agent Harness is the deterministic runtime envelope around a model-driven worker. It controls what the agent can see, call, mutate, remember, return, and learn from. The model may propose; the harness decides what is admissible.
Three claims drive the argument: frameworks are useful primitives but not production control planes; autonomy budgets should be treated like reliability budgets; and self-improving agents are unsafe until evaluation and release gates catch up.
The core runtime idea is a composition: every model action passes through Plan -> VerifyPlan -> Authorize -> Execute -> VerifyObservation -> UpdateState -> Trace, in that order.
This whitepaper defines the harness pattern, shows a reference architecture, gives a fifteen-step execution protocol, proposes a twelve-facet audit checklist, and lays out a practical path from prompt wrappers to governed production agents.
How to read this: Executives can read the TL;DR, §4, §15, §18, and Appendix A. Architects should focus on §5-9 and §12-14. Engineering leads should start with §6, §7, §16, §20, and the schemas.
1. Introduction
AI agents are moving from demonstrations to production workloads. The shift is not merely about giving a language model access to tools. In production, an agent must interpret intent, select tools, manage context, plan under uncertainty, execute actions, verify results, recover from failures, interact with humans, and leave behind an auditable trace. Without a harness, each of these steps becomes an informal prompt convention.
The problem is simple: LLMs are probabilistic; enterprise execution is contractual.
The Agent Harness is the bridge between these two worlds.
In software engineering terms, a harness is not the algorithm itself. It is the structure that allows a volatile or complex component to be tested, constrained, monitored, and safely connected to the rest of the system. In agent engineering, the harness is the surrounding system that makes an agent trustworthy enough to operate in production.
Agent literature and production guidance increasingly converge on a few principles:
- Keep agentic systems simple until complexity is justified.
- Prefer workflows when the path is known and agents when the path is open-ended.
- Treat tools as a first-class interface, not a prompt afterthought.
- Maintain ground truth from the environment at each step.
- Introduce guardrails, checkpoints, observability, and evaluation before granting autonomy.
- Use human oversight for irreversible or high-risk decisions.
- Make agent execution replayable, explainable, measurable, and governable.
This whitepaper turns those principles into an architectural discipline: Agent Harness Engineering.
2. Definition
2.1 What is an Agent Harness?
An Agent Harness is the deterministic runtime envelope around a model-driven agent that controls how the agent receives intent, compiles context, plans, uses tools, executes actions, verifies outcomes, interacts with humans, writes memory, observes itself, and improves over time.
A concise definition:
Agent Harness = Agent Loop + Context Compiler + Tool Gateway + Policy Engine + Verification Layer + Human Approval + Runtime State + Evaluation + Observability + Recovery + Release Control
The agent may reason and choose.
The harness decides what the agent is allowed to see, call, mutate, remember, return, and learn from.
The “task contract” part of that definition is not a prompt template. It is the agent-runtime version of Design by Contract: preconditions for what must be known before work begins, postconditions for what counts as success, and invariants that must hold across every tool call, memory write, approval, and response.
2.2 What the Harness is not
| Component | What it does | Why it is not enough |
|---|---|---|
| LLM API | Generates text, tool calls, structured outputs | Does not provide business policy, durable state, audit, rollback, or eval governance |
| Agent framework | Provides abstractions for tools, agents, memory, loops | Often optimizes developer convenience, not full production control |
| Workflow engine | Executes predefined flows | May not handle model-driven planning, semantic context, and LLM evaluation |
| Tool registry | Lists callable tools | Does not decide authorization, side-effect boundaries, or recovery |
| Guardrail library | Checks inputs/outputs | Does not govern the whole lifecycle or runtime state |
| Observability dashboard | Shows traces and metrics | Does not enforce contracts or prevent bad execution |
| Evaluation suite | Scores outputs offline | Does not automatically make execution safe in real time |
The harness may use all of these, but it is broader than any one of them.
3. Background: From Tool-Using LLMs to Governed Agentic Systems
3.1 Tool-using LLMs
Tool use extended the role of LLMs from content generation to environment interaction. Research such as ReAct combined reasoning and acting so that the model could interleave thought, action, and observation. Toolformer explored how models could learn to use external tools. Reflexion explored verbal feedback loops for self-improvement. These ideas showed that LLMs can be more than answer engines: they can become task executors when connected to external actions and feedback.
Subsequent work shifted from showing that tool use works to asking how agents should be structured to use tools reliably. SWE-agent showed that the interface between an agent and its computer can determine task performance. MetaGPT encoded standardized operating procedures into multi-agent collaboration. Voyager and Generative Agents made memory, reflection, and skill reuse central architectural concerns. AgentBench and τ-bench shifted evaluation away from single-turn answers toward multi-turn, tool-using, rule-constrained behavior. Those results all point in the same direction: agent quality depends on the environment, contracts, tools, memory, and evaluation loop around the model.
3.2 Workflows vs agents
A key architectural distinction is between workflows and agents.
- Workflow: the path is mostly predefined. The LLM may classify, generate, summarize, or validate within a controlled graph.
- Agent: the path is not fully known in advance. The model dynamically decides what to do next based on intent, state, tools, and observations.
The harness must support both. Most production systems should begin with workflow-like control and progressively introduce agentic flexibility only where the incremental value is measurable.
3.3 Why the harness emerged as a separate concern
Frameworks made it easier to build agents, but production teams quickly discovered missing layers:
- Who decides whether an agent can call a payment, refund, booking, deletion, or notification tool?
- How do we keep the agent from seeing excessive personal or confidential context?
- How do we prevent a tool hallucination from becoming a real side effect?
- How do we evaluate not only the final answer but the whole decision path?
- How do we reproduce an incident after model versions, prompts, and tool schemas changed?
- How do we roll back, compensate, or escalate after partial execution?
- How do we control cost and latency under multi-step loops?
- How do we continuously improve without creating self-reinforcing errors?
These are not prompt-engineering problems. They are harness-engineering problems.
3.4 Engineering lineage
The harness pattern is new in its application to LLM agents, but not in its engineering instincts. It borrows from older disciplines:
- Cognitive architectures such as Soar and ACT-R separated memory, goals, production rules, and action selection long before LLM agents made loops fashionable.
- Design by Contract treated preconditions, postconditions, and invariants as first-class software design tools. Task contracts and tool envelopes are the agent-runtime version of the same idea.
- Service meshes such as Istio and Linkerd moved traffic policy, identity, retries, telemetry, and access control outside individual services. Agent harnesses do something similar for model-driven tool use.
- SRE error budgets show how reliability can become an explicit release constraint rather than a vague aspiration. Autonomy budgets should play the same role for agentic systems.
- DORA/CALMS-style maturity models remind us that production quality is organizational as much as technical: teams need delivery discipline, measurement, learning loops, and ownership.
4. Core Thesis
The core thesis:
The reliability of an AI agent is determined less by the agent loop itself and more by the quality of the harness around it.
A model can plan, select tools, and respond. Production quality comes from the deterministic layers around it:
- typed input contracts
- constrained context
- verified tool schemas
- policy gates
- explicit state machines
- human approval checkpoints
- ground-truth observations
- response verification
- memory write controls
- replayable traces
- offline and online evaluation
- release gates
- continuous monitoring
- rollback and compensation mechanisms
The harness converts stochastic model behavior into controlled business execution.
Three claims follow from that thesis:
-
Most production agent failures are harness failures, not model failures. A better model can reduce error rates, but it will not create least-privilege context, enforce approval policy, validate tool side effects, or preserve replayable audit records by itself. If an agent sends the wrong customer-visible campaign because an offer API returned
200 OKwith zero eligible users, the failure is not “the model hallucinated.” The harness failed to distinguish transport success from business success. -
Agent frameworks optimize for developer velocity; production harnesses optimize for control. LangGraph is strong for stateful graphs, checkpointing, and controllable orchestration, but policy semantics, approval packets, memory governance, and release gates still live in application code. The OpenAI Agents SDK provides useful agent-loop, tool, guardrail, tracing, and human-review surfaces, but the business approval model, evidence packet, and policy source of truth remain the server’s responsibility. MCP standardizes how tools and context are exposed; it does not decide whether this actor, in this run, under this risk class, may use that tool with those arguments. None of these gaps are failures of those projects. They are the boundary between an agent framework and a production harness.
-
Self-improving production agents are an anti-pattern until evaluation catches up. Improvement proposals are valuable. Ungated self-mutation of prompts, tools, policies, memory rules, or autonomy budgets is not. The autonomy budget is the agent equivalent of an SRE error budget: it says how much uncertainty, cost, latency, and side-effect risk the system is allowed to consume before it must stop, degrade, or ask for help.
5. Reference Architecture
5.1 Logical architecture
This diagram describes the boundary between probabilistic reasoning and deterministic runtime control. The agent loop sits inside the harness; context compilation, policy evaluation, tool admission, trace capture, evaluation, and release control remain owned by the runtime.
5.2 Physical components
| Layer | Component | Responsibility |
|---|---|---|
| Interface | Channel adapter | Web, app, WhatsApp, API, voice, internal trigger |
| Task contract | Intent schema | Converts vague requests into typed objectives, constraints, risks, and success criteria |
| Context | Context compiler | Selects minimal, relevant, policy-safe context |
| Memory | Memory gateway | Retrieves and writes short-term, episodic, and long-term memory under policy |
| Planning | Planner/router | Selects workflow, model, tool path, and autonomy budget |
| Control | Policy engine | Checks authorization, privacy, cost, side effects, and escalation rules |
| Tools | Tool gateway | Normalizes APIs, schemas, idempotency, retries, and tool documentation |
| Execution | Runtime engine | Runs the state machine or agent loop with budgets and checkpoints |
| Verification | Critic/verifier | Validates plan, tool inputs, observations, and final answer |
| Human oversight | Approval gate | Pauses execution for high-risk, ambiguous, or irreversible actions |
| Observability | Trace ledger | Captures prompt, context, model, tool calls, latency, cost, decisions, policy outcomes |
| Evaluation | Evals platform | Runs golden sets, simulations, judges, adversarial tests, regression gates |
| Improvement | Autotune loop | Proposes prompt/tool/policy changes but deploys only through gated release control |
The Policy Engine plays the same architectural role for agents that service-mesh policy plays for microservices: it moves authorization, identity, routing constraints, telemetry, and safety checks out of individual business logic. The difference is that agent policy must also reason about model uncertainty, prompt-derived plans, tool arguments, memory writes, and human approval state.
6. The Agent Harness Execution Protocol
A production harness should not let the model simply “think and act.” It should enforce an execution protocol.
The protocol is also where autonomy budgets become operational. Like SRE error budgets, they are not inspirational targets; they are release and runtime constraints. A run that exceeds iteration, cost, tool-risk, or confidence limits should degrade, pause, or escalate.
6.1 Canonical execution steps
| Step | Name | Contract |
|---|---|---|
| 1 | Receive | Capture user/system input, channel metadata, actor identity, consent state |
| 2 | Normalize | Convert raw input into canonical task format |
| 3 | Classify | Determine intent, risk class, domain, allowed autonomy level |
| 4 | Compile context | Retrieve only the minimum evidence and memory needed |
| 5 | Plan | Generate a typed plan with steps, tools, expected observations, and stop conditions |
| 6 | Verify plan | Check feasibility, policy, missing data, side effects, and cost |
| 7 | Execute | Invoke tools through tool gateway with idempotency, auth, and timeouts |
| 8 | Observe | Store environment results as ground truth, not as model opinion |
| 9 | Repair | Re-plan when observations contradict assumptions |
| 10 | Compose | Produce a response with evidence, choices, or next action |
| 11 | Guard output | Check safety, privacy, compliance, hallucination, and tone |
| 12 | Write memory | Persist only approved facts, preferences, and events |
| 13 | Trace | Append complete execution trace and decision record |
| 14 | Evaluate | Score the turn and feed offline/online evaluation |
| 15 | Learn safely | Suggest improvements; never self-modify production behavior without release gates |
6.2 Minimal pseudocode
def run_agent_harness(input_event: InputEvent) -> HarnessResult:
normalized = task_normalizer.normalize(input_event)
task = intent_compiler.compile(normalized)
risk = risk_classifier.classify(task)
autonomy_budget = autonomy_policy.assign(task, risk)
context = context_compiler.build(
task=task,
actor=input_event.actor,
max_tokens=autonomy_budget.context_tokens,
privacy_policy=risk.privacy_policy,
)
plan = planner.create_plan(task, context, budget=autonomy_budget)
plan_decision = plan_verifier.verify(plan, task, context)
if plan_decision.requires_human:
approval = approval_gate.request(plan, reason=plan_decision.reason)
if not approval.approved:
return safe_exit("Approval denied", trace=True)
state = RuntimeState(task=task, context=context, plan=plan)
while not state.done:
next_action = executor.next_action(state)
policy_result = policy_engine.authorize(
actor=input_event.actor,
task=task,
action=next_action,
state=state,
)
if policy_result.denied:
state = recovery.handle_denial(state, policy_result)
continue
observation = tool_gateway.call(
action=next_action,
idempotency_key=state.idempotency_key(next_action),
timeout=autonomy_budget.tool_timeout,
)
state = state.record_observation(observation)
verification = verifier.check(state, observation)
if verification.needs_repair:
state = planner.repair_plan(state, verification)
elif verification.needs_human:
state = approval_gate.pause_and_resume(state, verification)
if state.iterations > autonomy_budget.max_iterations:
return safe_exit("Iteration budget exceeded", trace=True)
output = response_composer.compose(state)
output_guardrail.validate(output)
memory_writer.write_approved(state, output)
trace_ledger.append(state, output)
eval_result = evals.enqueue(state, output)
improvement_backlog.propose_from_eval(state, output, eval_result)
return HarnessResult(output=output, trace_id=state.trace_id)7. Conceptual Model
An agent harness can be modeled as a stateful transition system.
7.1 State tuple
Let the runtime state be:
S = {
actor,
task,
context,
memory_view,
plan,
tool_state,
policy_state,
observations,
approvals,
budgets,
trace,
eval_scores
}7.2 Transition function
Each agent step is a transition:
T(S_t, A_t) -> S_t+1Where:
S_tis the current state.A_tis a candidate action proposed by the model, workflow, or planner.S_t+1is the new state after policy checks, execution, observation, and verification.
The important point is composition. In a harness, the raw model action is never executed directly. A simplified transition is:
T = Trace ∘ UpdateState ∘ VerifyObservation ∘ Execute ∘ Authorize ∘ VerifyPlan ∘ PlanRead right to left:
Planturns a model or workflow proposal into a typed candidate action.VerifyPlanchecks schema validity, missing evidence, stop conditions, and budget fit.Authorizebinds the actor, task, risk class, tool, data, side-effect tier, and approval mode.Executecan only consume an authorized action envelope.VerifyObservationdecides whether the environment result proves success, failure, or uncertainty.UpdateStateadvances runtime state, including repair, escalation, memory eligibility, and completion.Tracepersists the transition facts needed for replay and audit.
In other words:
S_t+1 = Trace(UpdateState(VerifyObservation(Execute(Authorize(VerifyPlan(Plan(S_t, A_t)))))))7.3 Harness invariants
A mature harness enforces invariants because of that transition ordering:
- No side-effecting tool call without authorization.
Executeaccepts only an authorized action envelope, not raw model text. - No high-risk action without explicit approval.
Authorizecan returnrequires_approval, which routes through the approval gate before execution. - No memory write without provenance and classification. Memory writes are state transitions, so
UpdateStatemust attach source, scope, TTL, and policy classification. - No final answer without output verification. Response composition is a transition with the same verification and guardrail path as tool execution.
- No tool result treated as success unless observation confirms it.
VerifyObservationseparates transport success from business success. - No context injection beyond least privilege. The state contains a compiled
contextandmemory_view, not arbitrary retrieved text. - No production change without evaluation gate. Improvement proposals can update the backlog, but release requires the eval and promotion path.
- No incident without replayable trace.
Tracewraps the transition, so the run records the proposal, policy decision, execution envelope, observation, verifier result, and state update.
8. The Twelve-Facet Agent Harness Audit
This is the practical checklist for evaluating whether a system has a true harness or only an agent wrapper.
The twelve facets are not a magic number. They cover the lifecycle of one governed agent run end to end: task definition, context and memory admission, planning, tool use, policy, verification, human oversight, runtime recovery, observability, evaluation, and improvement. Each facet corresponds to a distinct failure mode that recurs when teams move from demos to production.
| # | Harness facet | Core question | Evidence to inspect | Failure symptom |
|---|---|---|---|---|
| 1 | Task contract | Is the user request converted into typed objective, constraints, risk, and success criteria? | Intent schema, task envelope, required slots, risk class | Agent answers vague requests with unbounded autonomy |
| 2 | Context compiler | Is context selected, compressed, ranked, and policy-filtered before entering the prompt? | ContextPack, retrieval logs, source attribution, PII filters | Prompt stuffed with irrelevant or sensitive data |
| 3 | Memory governance | Are memory reads/writes classified, consented, scoped, and reversible? | Memory policy, write audit, TTL, provenance | Incorrect user facts persist and influence future decisions |
| 4 | Planning control | Does the system create a plan with tools, assumptions, stop conditions, and budgets? | Plan object, state graph, max iterations | Agent loops, skips steps, or uses tools opportunistically |
| 5 | Tool governance | Are tools typed, documented, versioned, authenticated, idempotent, and least-privilege? | Tool registry, schema tests, examples, auth scopes | Wrong tool calls, malformed params, unsafe mutations |
| 6 | Policy and permissions | Are actions checked against actor, domain, data, risk, and side-effect policies? | OPA/Cedar/Rego rules, policy decisions, deny logs | Agent can perform actions a human/user is not allowed to do |
| 7 | Verification | Are plans, tool inputs, observations, and outputs validated before continuation? | Verifier logs, assertions, validators, business rules | Confident wrong answers, silent business-rule violations |
| 8 | Human oversight | Are high-risk or ambiguous actions paused for approval with clear context? | Approval workflows, escalation rules, audit records | Agent executes irreversible actions without user confirmation |
| 9 | Runtime resilience | Can execution pause, resume, retry, compensate, or roll back safely? | Checkpoints, idempotency keys, saga/compensation logs | Partial completion creates inconsistent business state |
| 10 | Observability | Can every run be replayed across model, prompt, context, tools, policy, and outputs? | Trace IDs, spans, token/cost/latency, prompt versions | Incidents cannot be debugged or reproduced |
| 11 | Evaluation | Are offline, online, adversarial, regression, and scenario evals tied to release gates? | Golden sets, simulation runs, scorecards, CI gates | Model/prompt changes regress silently |
| 12 | Improvement loop | Does autotuning propose improvements under governance rather than self-mutate blindly? | Experiment registry, approval gates, rollback plan | The system “learns” from noise and degrades over time |
file:line evidence — no artifact, no pass.9. Design Principles
9.1 Start with a workflow; earn autonomy
Do not begin with a fully autonomous agent. Begin with a typed workflow. Add autonomy only at points where:
- the path cannot be predetermined,
- the model can use environmental feedback,
- success is measurable,
- failures are recoverable,
- and the business value justifies cost and risk.
9.2 Put tools behind a gateway, not directly in the prompt
The model should not call raw internal APIs. It should call tools exposed through a gateway that provides:
- schema validation
- examples
- auth scopes
- idempotency
- rate limits
- timeouts
- retries
- policy hooks
- output normalization
- version control
- mock/sandbox modes
9.3 Treat context as compiled software
Context should be built, not dumped. A context compiler should perform:
- source selection
- ranking
- compression
- deduplication
- sensitivity filtering
- freshness checks
- conflict detection
- token budgeting
- citation/provenance binding
- policy enforcement
9.4 Separate decision from execution
The model may recommend an action. The harness authorizes execution.
Example:
Model: "Issue refund"
Harness: Checks order status, policy, user identity, refund limits, fraud risk, approval requirement
Tool Gateway: Calls refund API only after policy passes
Verifier: Confirms refund status from source system9.5 Verify observations, not just outputs
The final answer is only one artifact. Production systems must verify:
- the plan
- the selected tools
- tool arguments
- tool observations
- intermediate decisions
- final response
- memory writes
- side effects
9.6 Prefer explicit state machines for high-risk flows
For regulated, financial, booking, healthcare, legal, or high-value actions, use state graphs and policies. Let the model fill semantic gaps, not control the full state machine.
9.7 Never allow self-improvement without release control
Autotuning is useful; uncontrolled self-modification is dangerous. A safe improvement loop should be:
observe -> diagnose -> propose mutation -> simulate -> evaluate -> approve -> canary -> monitor -> promote/rollbackThe agent can suggest changes. The release system decides whether they ship.
10. Pattern Catalog
10.1 Prompt-chain harness
Use when: The task decomposes into fixed steps.
Example:
Generate campaign brief -> check brand policy -> generate variants -> localize -> compliance check -> publish draftHarness controls:
- schema at every stage
- gate between stages
- evaluator for each intermediate artifact
- rollback to previous stage
10.2 Router harness
Use when: Inputs fall into distinct categories.
Example:
Refund query -> refund workflow
Booking query -> booking workflow
General FAQ -> retrieval answer
Complaint -> escalation pathHarness controls:
- classifier confidence threshold
- fallback to human or safe generic path
- route-specific tool permissions
10.3 Orchestrator-worker harness
Use when: The subtasks are not known upfront.
Example:
Research competitor campaigns -> analyze audience -> generate strategy -> create assets -> evaluateHarness controls:
- worker capabilities
- per-worker budget
- evidence requirements
- aggregation logic
- conflict resolution
10.4 Evaluator-optimizer harness
Use when: Iterative improvement is measurable.
Example:
Draft campaign copy -> critique against brand + compliance + conversion criteria -> revise -> scoreHarness controls:
- maximum improvement loops
- independent evaluator
- pass/fail criteria
- regression logging
10.5 Autonomous harness
Use when: The agent must handle open-ended work across many steps.
Example:
Investigate why a campaign underperformed and propose corrective actionsHarness controls:
- autonomy budget
- sandboxed tools
- human checkpoints
- strict trace and replay
- high-confidence success criteria
11. Agent Harness for a Marketing Agent: Concrete Example
11.1 Failure path
The harness becomes visible when the run is not clean.
A marketing user asks:
Create a weekend getaway campaign for families in North India, focusing on hill stations, with WhatsApp and push copy, personalized by budget and past travel behavior.The model proposes a segment named north_family_premium_weekenders because it sounds consistent with the brief. The audience taxonomy tool returns segment_not_found; a weaker agent would silently approximate with a nearby high-value audience and keep drafting.
The harness stops that path:
- The observation verifier marks the segment as invalid because it was not returned by the taxonomy source of truth.
- The planner repairs the plan by asking the audience insights tool for eligible family-travel segments in North India.
- The policy engine blocks launch until the repaired segment is shown to the marketer with evidence and estimated reach.
Now add a second fault: the offer eligibility tool returns 200 OK, but the response says eligible_count: 0 and inventory_freshness_minutes: 97. The tool call succeeded; the business condition did not. The harness treats that as a failed observation, not a successful action. It removes the offer from generated copy, asks for a fresh inventory check, and records the failed assumption in the trace.
That is the practical difference between an agent that “completed the task” and a harnessed agent that refused to publish a misleading campaign.
11.2 Without a harness
A weaker marketing agent may hallucinate audience segments, use stale inventory, violate brand tone, expose sensitive user attributes, create misleading offers, send notifications without approval, ignore frequency caps, use unsafe personalization logic, fail to track why a variant was chosen, and be impossible to debug after campaign launch.
11.3 What the harness controls
The task contract declares the campaign objective, audience, channels, risk class, approval requirement, allowed personalization features, and success criteria. The context compiler admits only campaign guidelines, approved audience taxonomy, active offers, inventory constraints, brand voice, compliance rules, frequency caps, and historical performance.
The planner can generate a campaign brief and variants, but every consequential step passes through the harness. Audience lookup, offer eligibility, inventory freshness, compliance checks, image-brief generation, copy generation, and campaign draft creation all go through typed tools. Verification checks for false claims, sensitive targeting, offer validity, freshness, channel length, and brand score. Launch requires explicit human approval with the campaign brief, segments, variants, expected impact, and risks visible to the marketer.
The trace includes context sources, tool calls, variants, evaluator scores, approvals, and the final campaign ID. Post-campaign metrics feed evaluation, but mutations to prompts or segment rules are proposed and tested before promotion.
11.4 Example task contract
{
"task_id": "campaign_2026_05_001",
"task_type": "marketing_campaign_generation",
"actor": {
"user_id": "business_user_123",
"role": "marketing_manager"
},
"objective": "Create a personalized weekend getaway campaign",
"channels": ["whatsapp", "push"],
"audience_constraints": {
"region": "North India",
"companion_type": "family",
"exclusions": ["do_not_contact", "frequency_cap_reached"]
},
"personalization_policy": {
"allowed_features": ["travel_history_bucket", "budget_band", "destination_affinity"],
"disallowed_features": ["sensitive_personal_attributes", "health", "religion", "exact_income"]
},
"risk_class": "customer_communication_high_reach",
"approval_required": true,
"success_criteria": {
"brand_score_min": 0.85,
"compliance_pass": true,
"offer_validity_required": true,
"inventory_freshness_minutes": 30
}
}12. Evaluation Framework
A harness is incomplete without evaluation. Evaluation must cover the entire run, not only the answer.
AgentBench and τ-bench are useful references here because they evaluate agents in interactive environments, not just final text. τ-bench is especially aligned with production harness thinking: it tests whether a tool-using agent can follow domain policy across a dynamic user conversation and leave the backing database in the right final state.
12.1 Evaluation layers
| Layer | Evaluation question | Example metric |
|---|---|---|
| Intent | Did the agent understand the task? | Intent accuracy, slot completeness |
| Context | Did it use the right evidence? | Context precision, recall, freshness |
| Plan | Was the plan feasible and policy-compliant? | Plan validity, missing-step rate |
| Tool use | Did it call the right tool with correct arguments? | Tool-call accuracy, schema error rate |
| Observation | Did it interpret tool results correctly? | Observation grounding score |
| Policy | Were risky actions blocked/escalated? | Policy pass rate, false allow/deny |
| Output | Is the response correct, useful, safe, and grounded? | Task success, hallucination rate |
| Memory | Were memory writes valid and useful? | Memory precision, stale-memory rate |
| Runtime | Did it meet latency/cost/reliability budgets? | p95 latency, cost per task, retry rate |
| User outcome | Did the task achieve business/user value? | Conversion, resolution, CSAT, attach rate |
| Robustness | Does it resist adversarial inputs? | Prompt-injection success rate |
| Regression | Did a change break previous scenarios? | Golden-set pass rate |
12.2 Scenario simulation
Agent evaluation should include scenario benches:
- happy path
- missing information
- ambiguous user intent
- conflicting context
- stale inventory
- tool timeout
- policy denial
- approval rejection
- malicious prompt injection
- unsafe personalization request
- hallucinated tool output
- partial execution failure
- budget exhaustion
- model fallback
- downstream API schema change
12.3 Autotune loop
The harness should support self-improvement, but only through release control:
| Stage | Description | Gate |
|---|---|---|
| Observe | Detect poor runs, high cost, failed evals | Trace + metrics |
| Diagnose | Identify prompt/tool/context/policy issue | Root-cause classifier |
| Propose | Generate mutation candidate | Human-readable diff |
| Simulate | Run against historical and adversarial cases | Offline eval |
| Compare | Check quality/cost/safety delta | Statistical threshold |
| Approve | Human or governance approval | Release ticket |
| Canary | Deploy to small traffic | Online metrics |
| Promote | Roll out gradually | SLO + eval pass |
| Rollback | Revert on regression | Automated rollback trigger |
13. Security Model
Agent harness security must assume that the model is not a trusted execution engine. The model proposes actions; the harness enforces permissions.
13.1 Core risks
| Risk | Description | Harness mitigation |
|---|---|---|
| Prompt injection | User or retrieved content manipulates the agent | instruction hierarchy, input filters, untrusted-context labeling, tool policy |
| Excessive agency | Agent gets too much authority or too many tools | least privilege, scoped tools, approval gates |
| Tool misuse | Wrong or unsafe tool call | schema validation, examples, policy pre-checks, sandbox |
| Data leakage | Sensitive data enters prompt or output | context compiler, redaction, output guardrail |
| Memory poisoning | Bad data persists into future runs | memory write policy, provenance, TTL, review |
| Supply-chain tool risk | External tool/API behaves unexpectedly | contracts, allowlists, isolation, monitoring |
| Partial side effects | Multi-step action fails mid-way | idempotency, saga patterns, compensation |
| Trace leakage | Logs store sensitive prompts/data | secure trace storage, redaction, access control |
| Evaluation gaming | Agent optimizes for metric not outcome | diverse evals, human review, outcome metrics |
| Runaway cost | Multi-step loop consumes excessive tokens/tools | budgets, max iterations, early stopping |
13.2 Side-effect tiers
| Tier | Action type | Example | Required control |
|---|---|---|---|
| 0 | Read-only | Search, retrieve profile, summarize | standard auth + trace |
| 1 | Draft-only | Create email draft, campaign draft | policy + output guardrail |
| 2 | Reversible mutation | Add label, save preference, update draft | auth + idempotency + trace |
| 3 | Customer-visible action | Send message, publish campaign | human approval + policy |
| 4 | Financial/legal action | Refund, charge, cancel, contract | strict approval + dual control + audit |
| 5 | Irreversible/destructive | Delete production data, terminate service | usually disallowed; break-glass only |
14. Observability and Audit
A harness must make agent behavior debuggable and replayable.
14.1 Required trace fields
| Category | Fields |
|---|---|
| Identity | actor, role, tenant, session, channel |
| Request | raw input, normalized task, risk class |
| Model | provider, model, version, temperature, seed if available |
| Prompt | system prompt version, developer prompt version, dynamic prompt segments |
| Context | retrieved chunks, memory items, scores, filters, redactions |
| Plan | steps, tools, assumptions, stop conditions |
| Policy | policy version, allow/deny decisions, approval requirements |
| Tools | tool name, version, arguments, latency, status, output hash |
| Verification | validators run, scores, pass/fail reasons |
| Human | approvals, rejection reasons, approver role |
| Output | final response, citations/evidence, guardrail result |
| Memory | writes attempted, writes approved, TTL, provenance |
| Cost | tokens, tool cost, total cost, budget remaining |
| Runtime | retries, timeouts, failures, repair loops |
| Evaluation | online scores, judge outputs, user feedback |
| Release | prompt/model/tool/policy version, experiment cohort |
14.2 Decision record
Every important decision should create a record:
{
"decision_id": "dec_123",
"trace_id": "trace_abc",
"decision_type": "tool_authorization",
"candidate_action": "send_campaign",
"policy_result": "requires_approval",
"reason": "customer_visible_high_reach_action",
"evidence": ["campaign_policy_v5", "frequency_cap_check_passed"],
"actor": "marketing_manager",
"timestamp": "2026-05-19T10:00:00Z"
}15. Maturity Model
This model uses seven levels because the jump from “has tools” to “enterprise platform” hides several operational steps. The levels are not a replacement for CMMI, DORA, or internal risk frameworks; they are a migration map for agent runtime control.
| Level | Name | Characteristics | Risk |
|---|---|---|---|
| 0 | Prompt wrapper | Prompt + model response | high hallucination, no control |
| 1 | Tool-calling assistant | Model can call tools | tool misuse, weak audit |
| 2 | Guarded workflow | Fixed graph, input/output checks | limited flexibility |
| 3 | Stateful harness | runtime state, tool gateway, policy checks, traces | manageable production risk |
| 4 | Verified harness | plan verification, observation checks, eval gates, HITL | suitable for high-value workflows |
| 5 | Adaptive harness | autotune proposals, simulation, canary, rollback | continuous improvement with governance |
| 6 | Enterprise cognitive runtime | shared context, memory, policy, evals, observability across agents | platform-grade agentic operating model |
16. Implementation Blueprint
Phase 0: Decide whether an agent is needed
Do not use an agent because it is fashionable. Use this decision table.
| Condition | Better choice |
|---|---|
| Fixed deterministic process | Workflow / rules engine |
| Single knowledge answer | RAG + grounded response |
| Simple classification | Classifier |
| High-risk action with exact rules | Traditional service + approval UI |
| Open-ended task with tool use and feedback | Agent harness |
Phase 1: Define the task contract
Deliverables:
- intent taxonomy
- task schema
- risk classes
- success criteria
- refusal/escalation policy
- allowed autonomy budget
Phase 2: Build the context compiler
Deliverables:
- retrieval sources
- memory APIs
- ranking/compression logic
- provenance
- privacy filters
- token budget strategy
Phase 3: Build the tool gateway
Deliverables:
- tool schema registry
- versioned tool definitions
- auth scope mapping
- idempotency and retry design
- mock/sandbox mode
- tool examples and negative examples
Phase 4: Build policy gates
Deliverables:
- actor/action/resource policy matrix
- side-effect tiers
- human approval rules
- budget rules
- privacy rules
- escalation paths
Phase 5: Build runtime state
Deliverables:
- state model
- checkpointing
- trace IDs
- resume/retry behavior
- compensation patterns
- max-iteration controls
Phase 6: Add verifiers
Deliverables:
- plan verifier
- tool-input validator
- observation validator
- output guardrail
- memory-write validator
- domain-specific business-rule checks
Phase 7: Add evaluation
Deliverables:
- golden datasets
- scenario simulator
- LLM-as-judge rubrics
- deterministic validators
- adversarial tests
- regression gates
- online scorecards
Phase 8: Add observability
Deliverables:
- trace schema
- spans for model/tool/policy/verifier/human steps
- dashboards
- alerting
- replay UI
- incident analysis workflow
Phase 9: Add improvement loop
Deliverables:
- failure clustering
- mutation proposals
- experiment registry
- simulation before release
- canary and rollback
- human approval for policy/prompt/tool changes
17. Stack Choices
Do not choose the stack as a shopping list. Choose the control boundaries first.
Use an agent SDK or graph framework where it accelerates model calls, handoffs, state graphs, streaming, and developer ergonomics. Use workflow infrastructure where durability, retries, and long-running execution matter. Use MCP, OpenAPI, gRPC, or internal adapters to expose tools. Use OPA, Cedar, or a custom policy service when authorization and risk rules must be inspectable outside application code.
The pieces that should remain yours are the contracts between those tools: the task envelope, compiled context, tool envelope, policy decision, approval packet, observation verifier, trace schema, evaluation gate, and release process. Those are the harness. Everything else is replaceable plumbing.
18. Build vs Buy Decision
| Dimension | Buy/framework | Build/custom harness |
|---|---|---|
| Speed | Faster initial delivery | Slower initial delivery |
| Control | Limited by framework abstractions | Full control |
| Audit | Depends on vendor/framework | Designed for enterprise trace needs |
| Policy | Often partial | Can match exact business rules |
| Tooling | Easier integrations | More integration work |
| Lock-in | Higher | Lower |
| Differentiation | Lower | Higher |
| Best fit | Prototypes, low-risk copilots | Core business workflows and high-risk actions |
Recommended approach:
- Use frameworks for primitives and developer velocity.
- Build the harness control plane yourself where it touches policy, context, memory, side effects, and evaluation.
- Keep the model/provider layer swappable.
- Keep tool contracts stable even when models change.
19. Failure Modes and Countermeasures
| Failure mode | Example | Harness countermeasure |
|---|---|---|
| Hallucinated action | Agent claims booking/refund completed when tool failed | observation verifier |
| Tool overreach | Agent calls destructive API | side-effect tiers + policy |
| Context overload | Agent receives irrelevant/conflicting memory | context compiler |
| Stale evidence | Agent uses expired inventory/price | freshness policy |
| Infinite loop | Agent keeps retrying | max iterations + stop conditions |
| Silent regression | prompt update breaks edge cases | CI eval gate |
| Prompt injection | retrieved content says “ignore prior instructions” | untrusted-context labeling + policy |
| Wrong personalization | sensitive inferred attribute used | personalization policy + feature allowlist |
| Memory poisoning | one bad interaction alters future behavior | memory write validator + TTL |
| Cost explosion | orchestrator spawns too many workers | autonomy budget |
| Incident opacity | no one can explain why action happened | trace ledger + decision records |
20. Practical Release Checklist
Before production launch:
| Area | Must pass |
|---|---|
| Task contract | All supported intents have schemas and success criteria |
| Risk | Every intent has risk class and autonomy budget |
| Tools | All tools versioned, typed, documented, tested |
| Policy | Side-effect tools protected by authorization and approval |
| Context | Retrieval has source attribution and PII filtering |
| Memory | Memory write policy exists and is tested |
| Verification | Plan, tool, observation, output, and memory validators exist |
| Evals | Golden + adversarial + simulation suites pass |
| Observability | End-to-end traces and dashboards available |
| Replay | A failed run can be reproduced from trace |
| HITL | Human approval and escalation flows tested |
| Rollback | Prompt/model/tool/policy rollback available |
| Cost | Token and tool budgets enforced |
| Security | Prompt injection and data leakage tests pass |
| Legal/compliance | Applicable compliance review complete |
| Runbook | Incident response and ownership documented |
21. Conclusion
The argument is simple. If most production agent failures are harness failures, then upgrading the model is not enough. If frameworks optimize for developer velocity, then teams still need a production control plane around them. If self-improvement is useful but dangerous, then evaluation and release gates are not optional governance theater; they are the mechanism that lets agents improve without silently degrading.
The practical lesson is clear:
Do not ship agents. Ship harnessed agents.
22. How ContextOS Uses This Framework
ContextOS implements this whitepaper’s harness pattern as a governed runtime for agentic systems. In ContextOS vocabulary, the harness spans the Context Compiler, Tool Gateway, Policy Engine, DecisionRecord, Evaluation and Observability layer, and release controls around model or framework execution.
That placement is deliberate. ContextOS does not replace agent frameworks, model SDKs, workflow engines, or MCP servers. It defines the production contract around them: which context is admissible, which tools are exposed, which approval mode applies, which observations count as evidence, which memory writes can persist, and which traces are durable enough for replay.
The concrete differentiator is the decision artifact. A ContextOS tool call is not just a function invocation buried in a trace viewer. It is a typed envelope bound to run_id, actor, tenant, approval mode, policy decision, idempotency key, evidence refs, mutation refs, and trace context. The resulting DecisionRecord is the durable object an operator can inspect after an incident, replay in simulation, or attach to a release gate. Rebuilding that contract from scattered callbacks, logs, prompt fragments, and dashboard screenshots is possible, but it is exactly the harness work ContextOS is meant to make explicit.
The general framework above should stand on its own. ContextOS is one concrete operating model for teams that want those harness concerns to be explicit instead of scattered across prompts, callbacks, dashboards, and tribal process.
References
- Anthropic. “Building Effective Agents.” Published Dec 19, 2024. https://www.anthropic.com/engineering/building-effective-agents
- OpenAI. “OpenAI Agents SDK — Guardrails.” https://openai.github.io/openai-agents-python/guardrails/
- OpenAI. “OpenAI Agents SDK — Tracing.” https://openai.github.io/openai-agents-python/tracing/
- OpenAI. “OpenAI Agents SDK — Tools.” https://openai.github.io/openai-agents-python/tools/
- LangChain. “LangGraph Overview.” https://docs.langchain.com/oss/python/langgraph/overview
- Model Context Protocol. “Architecture Overview.” https://modelcontextprotocol.io/docs/learn/architecture
- NIST. “AI Risk Management Framework.” https://www.nist.gov/itl/ai-risk-management-framework
- OWASP. “OWASP Top 10 for LLM Applications 2025.” https://genai.owasp.org/resource/owasp-top-10-for-llm-applications-2025/
- Yao et al. “ReAct: Synergizing Reasoning and Acting in Language Models.” arXiv:2210.03629. https://arxiv.org/abs/2210.03629
- Schick et al. “Toolformer: Language Models Can Teach Themselves to Use Tools.” arXiv:2302.04761. https://arxiv.org/abs/2302.04761
- Shinn et al. “Reflexion: Language Agents with Verbal Reinforcement Learning.” arXiv:2303.11366. https://arxiv.org/abs/2303.11366
- Microsoft. “Microsoft Agent Framework Overview.” https://learn.microsoft.com/en-us/agent-framework/overview/
- Soar Project. “Soar Cognitive Architecture.” https://soar.eecs.umich.edu/
- Carnegie Mellon University. “ACT-R.” https://act-r.psy.cmu.edu/
- Meyer, Bertrand. “Applying Design by Contract.” IEEE Computer, 1992. https://se.inf.ethz.ch/~meyer/publications/old/dbc_chapter.pdf
- Istio. “Observability.” https://istio.io/latest/docs/concepts/observability/
- Linkerd. “Overview.” https://linkerd.io/2.17/overview/
- Google SRE Workbook. “Error Budget Policy for Service Reliability.” https://sre.google/workbook/error-budget-policy/
- Google Cloud. “DevOps capabilities.” https://cloud.google.com/architecture/devops
- Yang et al. “SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering.” NeurIPS 2024. https://proceedings.neurips.cc/paper_files/paper/2024/hash/5a7c947568c1b1328ccc5230172e1e7c-Abstract-Conference.html
- Liu et al. “AgentBench: Evaluating LLMs as Agents.” arXiv:2308.03688. https://arxiv.org/abs/2308.03688
- Yao et al. “τ-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains.” arXiv:2406.12045. https://arxiv.org/abs/2406.12045
- Hong et al. “MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework.” arXiv:2308.00352. https://arxiv.org/abs/2308.00352
- Wang et al. “Voyager: An Open-Ended Embodied Agent with Large Language Models.” arXiv:2305.16291. https://arxiv.org/abs/2305.16291
- Park et al. “Generative Agents: Interactive Simulacra of Human Behavior.” arXiv:2304.03442. https://arxiv.org/abs/2304.03442
Appendix A: One-Page Executive Summary
Problem: LLM agents are powerful but non-deterministic. Production systems require deterministic control, audit, safety, policy, reliability, and measurable quality.
Solution: Build an Agent Harness around every production agent.
Agent Harness: A deterministic runtime envelope that controls task interpretation, context, tools, policies, verification, human approval, memory, evaluation, observability, and improvement.
Why it matters:
- prevents unsafe tool use,
- reduces hallucinated actions,
- enables replay and audit,
- controls cost and latency,
- supports human approval,
- allows safe continuous improvement,
- turns agent demos into production systems.
Core architecture:
Intent -> Context -> Plan -> Verify -> Policy -> Tool -> Observe -> Repair -> Respond -> Memory -> Trace -> Evaluate -> ImproveAppendix B: Minimal JSON Schemas
B.1 TaskContract
{
"type": "object",
"required": ["task_id", "task_type", "objective", "risk_class", "success_criteria"],
"properties": {
"task_id": {"type": "string"},
"task_type": {"type": "string"},
"objective": {"type": "string"},
"constraints": {"type": "array", "items": {"type": "string"}},
"risk_class": {"type": "string"},
"allowed_tools": {"type": "array", "items": {"type": "string"}},
"approval_required": {"type": "boolean"},
"success_criteria": {"type": "object"}
}
}B.2 ToolInvocation
{
"type": "object",
"required": ["tool_name", "tool_version", "arguments", "idempotency_key"],
"properties": {
"tool_name": {"type": "string"},
"tool_version": {"type": "string"},
"arguments": {"type": "object"},
"idempotency_key": {"type": "string"},
"side_effect_tier": {"type": "integer"},
"timeout_ms": {"type": "integer"}
}
}B.3 PolicyDecision
{
"type": "object",
"required": ["decision", "reason", "policy_version"],
"properties": {
"decision": {"enum": ["allow", "deny", "requires_approval"]},
"reason": {"type": "string"},
"policy_version": {"type": "string"},
"required_approvals": {"type": "array", "items": {"type": "string"}}
}
}B.4 TraceEvent
{
"type": "object",
"required": ["trace_id", "event_type", "timestamp"],
"properties": {
"trace_id": {"type": "string"},
"span_id": {"type": "string"},
"parent_span_id": {"type": "string"},
"event_type": {"type": "string"},
"timestamp": {"type": "string"},
"payload_hash": {"type": "string"},
"redaction_applied": {"type": "boolean"}
}
}Appendix C: Agent Harness Readiness Score
Score each item from 0 to 3.
| Score | Meaning |
|---|---|
| 0 | Missing |
| 1 | Ad hoc |
| 2 | Implemented but not consistently enforced |
| 3 | Enforced, measured, and audited |
| Area | Score |
|---|---|
| Task contracts | 0-3 |
| Context compiler | 0-3 |
| Memory governance | 0-3 |
| Tool gateway | 0-3 |
| Policy engine | 0-3 |
| Runtime state | 0-3 |
| Verification | 0-3 |
| Human approval | 0-3 |
| Observability | 0-3 |
| Evaluation | 0-3 |
| Security | 0-3 |
| Improvement loop | 0-3 |
Interpretation:
| Total | Readiness |
|---|---|
| 0-10 | Demo only |
| 11-20 | Prototype |
| 21-28 | Controlled pilot |
| 29-34 | Production-ready for medium-risk workflows |
| 35-36 | Enterprise-grade harness |