Most agent systems still behave like a smart model sitting behind a tool menu. They can answer, retrieve, call APIs, and write memory, but the operator often has to infer the most important part of the run:
What did the system attend to? Which identity and goals shaped the response? Why was one action chosen over another? What got blocked? What did the system learn? What pressure or degraded reasoning state was visible before the answer was produced?
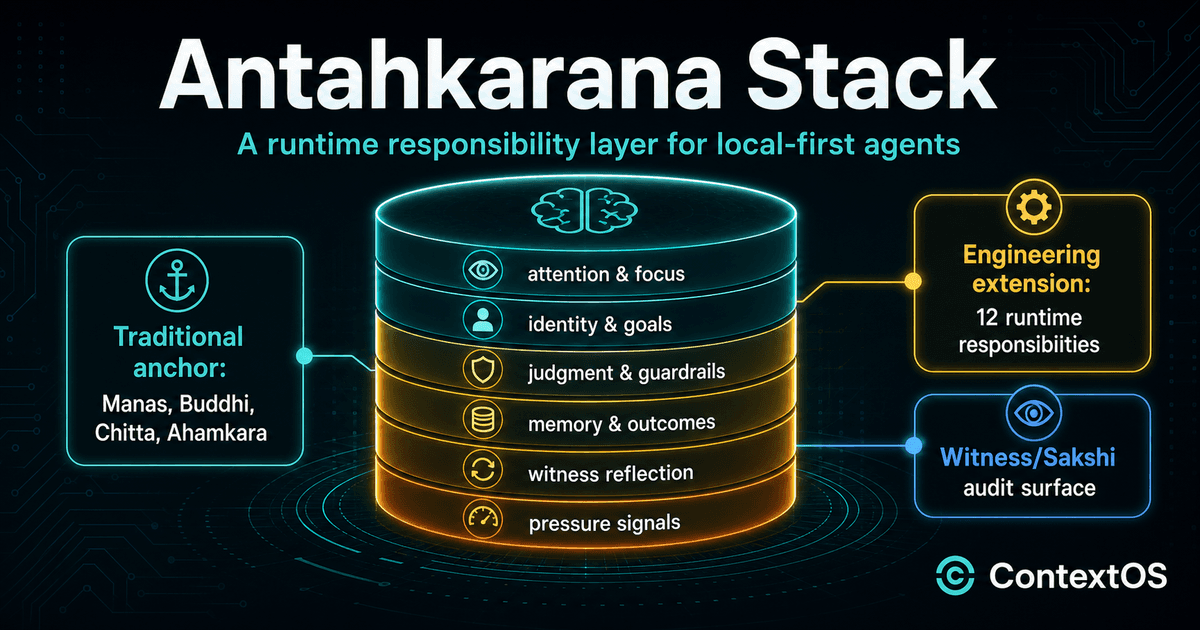
The Antahkarana Stack is a way to make those questions first-class. It is an engineering architecture inspired by Vedic inner-faculty explanations and Yoga-discipline concepts, but it is not a claim that a product runtime is scripture. The practical point is engineering, not ornament: put a structured cognitive layer above the execution substrate so every serious turn can pass through attention, identity, goals, judgment, guardrails, deliberation, action history, memory, and reflection.
In runtime terms, the stack is simple:
Antahkarana -> Kernel -> Providers / Tools / Local StateThe kernel still executes. Providers still generate. Tools still touch the world. Local state still stores traces, memories, files, indexes, and decisions. Antahkarana decides how the system should frame the work before, during, and after those execution steps.
That difference is what turns a prompt loop into a cognitive operating layer.
Source and interpretation note
This architecture is inspired by Vedic inner-faculty explanations and Yoga-discipline concepts, especially the Antahkaran framing described by Swami Ram Swarupji on Vedmandir: Mann or Manas, Buddhi, Chitta, and Ahankar or Ahamkara. Vedmandir also draws a strict distinction between the conscious Atma and the inner instruments made of Prakriti. In this post, Antahkarana is the product and stack name; Antahkaran is a common Hindi rendering.
The twelve-responsibility stack below is not claimed as a canonical scriptural taxonomy. It is an engineering translation for local-first agent runtimes. Traditional terms are used as disciplined metaphors for explicit runtime responsibilities, and the machine is not described as having Atma. The runtime has a witness-style audit surface, not a soul.
See the Vedmandir explanations of Antakaran and purification, Mann, Buddhi, Chitta, Ahankar, and Atma, and Buddhi, Mann, and Aatma for the source vocabulary that motivated this engineering analogy.
The traditional anchor
The traditional inspiration should stay small and precise. The core inner-faculty model is not twelve layers. It is anchored in four faculties:
| Faculty | Traditional role | Engineering analogy |
|---|---|---|
| Manas | Gathering, options, doubts, and active mental movement. | Attention, salience, and working-memory assembly. |
| Buddhi | Deciding and discriminating after the mind passes information forward. | Strategy selection, confidence calibration, and decision records. |
| Chitta | Store of impressions, memory, and the effects of actions. | Memory consolidation, recall, and promotion control. |
| Ahamkara | The sense of “I” and worldly identity. | Runtime identity, role, ownership, and constraint frame. |
Vedmandir’s cognitive sequence is also useful as inspiration: senses gather input, the mind receives it, the intellect decides, the Atma experiences or accepts, and action returns through the instruments. For an agent runtime, the analogy must stop before metaphysics. The system can expose input, attention, decision, action, memory, and reflection artifacts; it cannot claim conscious experience.
That boundary is important because the Antahkarana Stack is meant to make agents more governable, not more mystical.
The promise
The marketing version is:
Antahkarana gives local agents a nervous system.
The engineering version is:
Antahkarana turns implicit model behavior into inspectable layer outputs.
Those are the same claim at different altitudes. A local-first agent should not just produce a final answer. It should leave behind enough structure for an operator to know:
| Question | Antahkarana surface |
|---|---|
| What came in? | Indriya source normalization |
| What mattered? | Manas salience and working memory |
| What goal was active? | Sankalpa goal alignment |
| What identity shaped the turn? | Ahamkara runtime identity frame |
| What was decided? | Buddhi plan, confidence, and strategy |
| What was blocked or approved? | Viveka checks and Sabha deliberation |
| What happened? | Karma action ledger and outcome |
| What should be remembered? | Chitta consolidation |
| What did the system learn about itself? | Witness/Sakshi reflection and Bhava pressure signals |
That is why Antahkarana is powerful for explainability. It does not ask a model to explain itself after the fact. It gives the runtime named places to record the moving parts while the work happens.
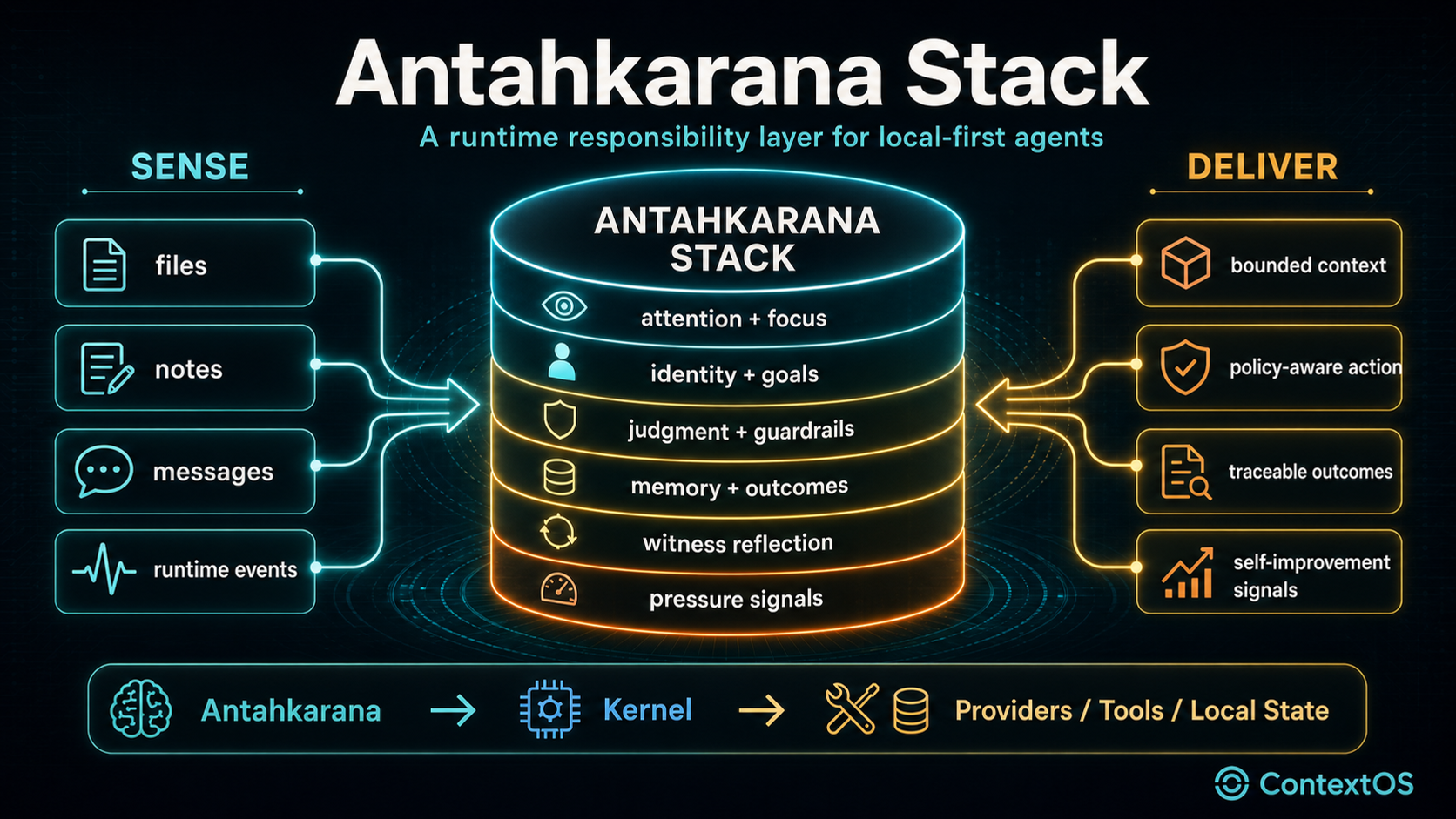
The stack is positioned above the execution substrate: it shapes attention, judgment, guardrails, memory, witness-style reflection, and pressure before the kernel touches tools or state.
Traditional terms vs engineering extension
The safer framing is to separate the source vocabulary from the product architecture.
| Class | Terms | Blog positioning |
|---|---|---|
| Traditional inner faculties | Manas, Buddhi, Chitta, Ahamkara | Core cognitive inspiration. |
| Adjacent Vedic/Yogic concepts | Indriya, Prana, Sankalpa, Viveka, Karma, Dharana | Disciplined metaphors for runtime responsibilities. |
| Engineering-only extensions | Sabha, Bhava Monitor, Witness/Sakshi reflection | Modern constructs for deliberation, pressure, audit, and recovery. |
That distinction protects the core claim. The post is not saying “Vedic scripture contains this software architecture.” It is saying the inner-faculty vocabulary gives builders a disciplined way to name runtime surfaces that are usually hidden inside prompts.
The twelve-responsibility runtime map
Antahkarana is easiest to understand as a proposed engineering loop with twelve runtime responsibilities plus a functional-state sidecar.
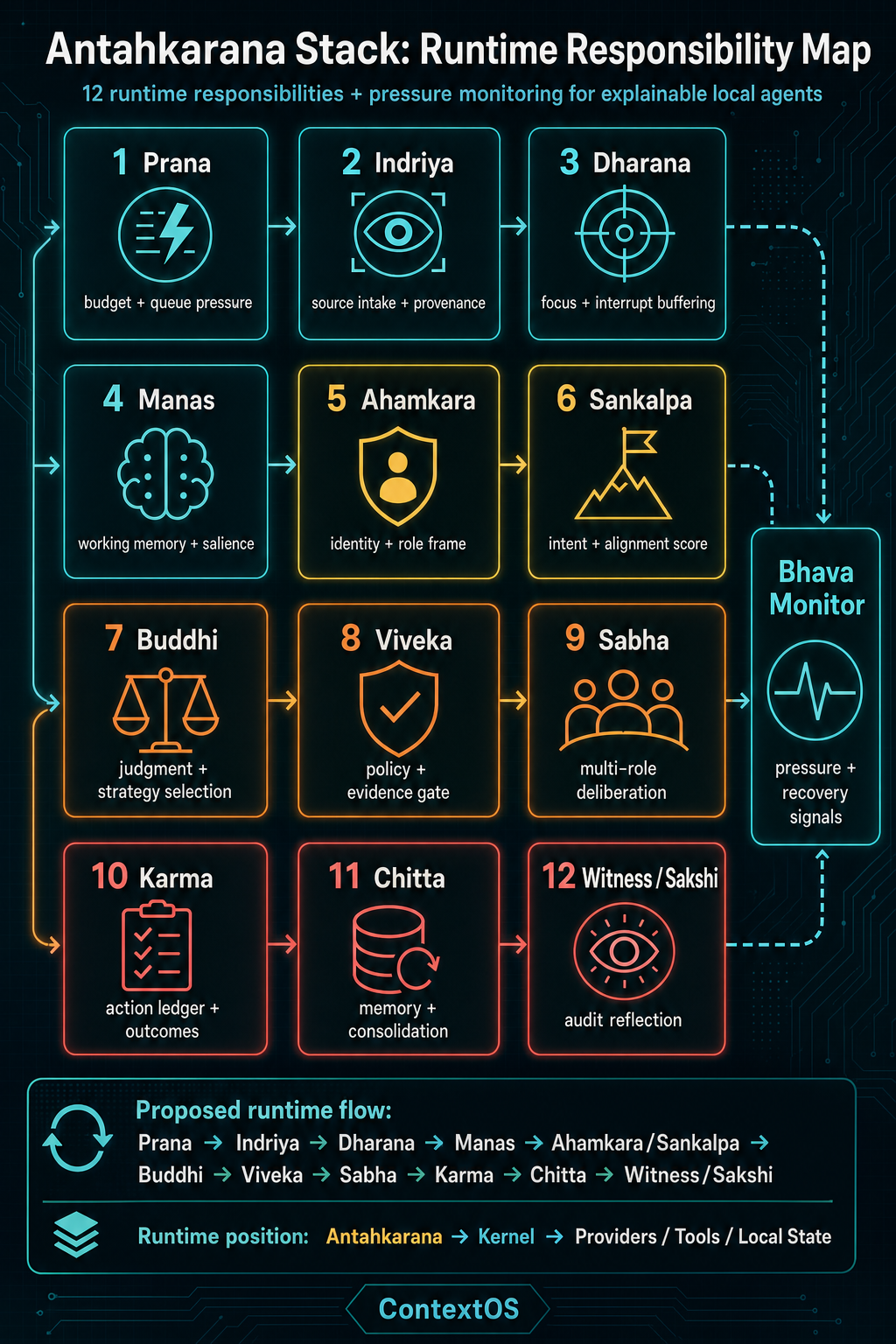
The runtime map extends the traditional inner-faculty inspiration into twelve engineering responsibilities. Bhava Monitor sits alongside the loop and feeds pressure and recovery signals into runtime behavior.
The proposed runtime flow is:
Prana -> Indriya -> Dharana -> Manas -> Ahamkara/Sankalpa -> Buddhi -> Viveka -> Sabha -> Karma -> Chitta -> Witness/SakshiEach layer has a small job. The value comes from the jobs being explicit.
| Runtime layer | Source status | Runtime responsibility |
|---|---|---|
| Prana | Engineering metaphor | Track runtime budget, energy, queue pressure, and admission control. |
| Indriya | Engineering metaphor | Normalize source intake, perception, payloads, and input provenance. |
| Dharana | Focus discipline | Control focus, buffer interrupts, and maintain attention lock. |
| Manas | Traditional Antahkaran faculty | Assemble working memory, salience, and active context. |
| Ahamkara | Traditional Antahkaran faculty | Maintain runtime identity, role, ownership, constraints, and the question “who am I acting as?” |
| Sankalpa | Engineering metaphor | Track active intent, goal commitment, and alignment score. |
| Buddhi | Traditional Antahkaran faculty | Select strategy, calibrate confidence, compare alternatives, and emit decision records. |
| Viveka | Engineering metaphor | Apply discernment, policy, risk checks, and evidence sufficiency. |
| Sabha | Runtime extension | Run multi-role deliberation across planner, critic, guardian, historian, and curator roles. |
| Karma | Engineering metaphor | Record action ledger, outcomes, regrets, and lessons. |
| Chitta | Traditional Antahkaran faculty | Consolidate memory, recall impressions, and control memory promotion. |
| Witness/Sakshi | Witness-style audit surface | Emit audit reflection, uncertainty, coherence, and quality reports without implying machine consciousness. |
| Bhava Monitor | Operational sidecar | Detect pressure, degraded reasoning conditions, and recovery needs. |
This is not a request for every deployment to run a huge agent bureaucracy. It is a decomposition. A narrow workflow can start with deterministic Prana, Manas, Buddhi, Viveka, Karma, and Chitta. A richer workflow can add identity, goals, deliberation, focus mode, and witness reporting. The architecture scales by making responsibilities visible, not by making every turn theatrical.
Why this matters for local-first agents
Local-first agents have a different trust posture from cloud-only assistants. They often sit near private notes, source code, documents, local tools, credentials, calendars, screenshots, and long-running work state. That proximity is useful only if the runtime can govern what the model sees and what the system does.
Antahkarana gives the local agent a middle layer between raw state and action.
Without that layer, the run tends to collapse into:
input -> retrieval -> prompt -> model -> tool call -> answerWith Antahkarana, the run can be shaped as:
input
-> source normalization
-> focus and salience
-> working-memory assembly
-> identity and goal alignment
-> strategy and confidence
-> guardrail and consensus checks
-> governed action
-> outcome ledger
-> memory consolidation
-> witness reflection and pressure reportingThat longer path is not slower for its own sake. It creates places to enforce policy and places to inspect failure.
If a run produced a confident wrong answer, the operator can ask whether Manas pulled the wrong working memory, Buddhi overestimated confidence, Viveka accepted thin evidence, Chitta recalled stale memory, or Witness/Sakshi reported poor coherence. The failure now has a shape.
The explainability shift
Many AI products market “explainability” as a paragraph written after the answer. That is weak explainability. It may be useful, but it is still generated prose.
Antahkarana supports stronger explainability because each layer can emit a structured impression:
- source and payload normalization from Indriya;
- focus locks and interrupt handling from Dharana;
- salience details and working-memory choices from Manas;
- identity cues from Ahamkara;
- active-goal alignment from Sankalpa;
- confidence, contradiction, and strategy from Buddhi;
- approval concerns from Viveka;
- deliberation votes from Sabha;
- action, outcome, regret, and lesson records from Karma;
- memory write or recall records from Chitta;
- uncertainty and coherence from Witness/Sakshi.
The final answer is no longer the only artifact. It is the last artifact in a chain.
That is the same design direction as the ContextOS five-plane model. Intelligence owns knowledge and memory. Context compiles bounded input. Decision plans and verifies. Action touches the world through governed tools. Trust applies policy, replay, approval, and evaluation. Antahkarana is a cognitive layer that can sit across those planes and add human-legible state to the run.
From request to reliable action
The simplest way to see the stack is as a reliability pipeline.
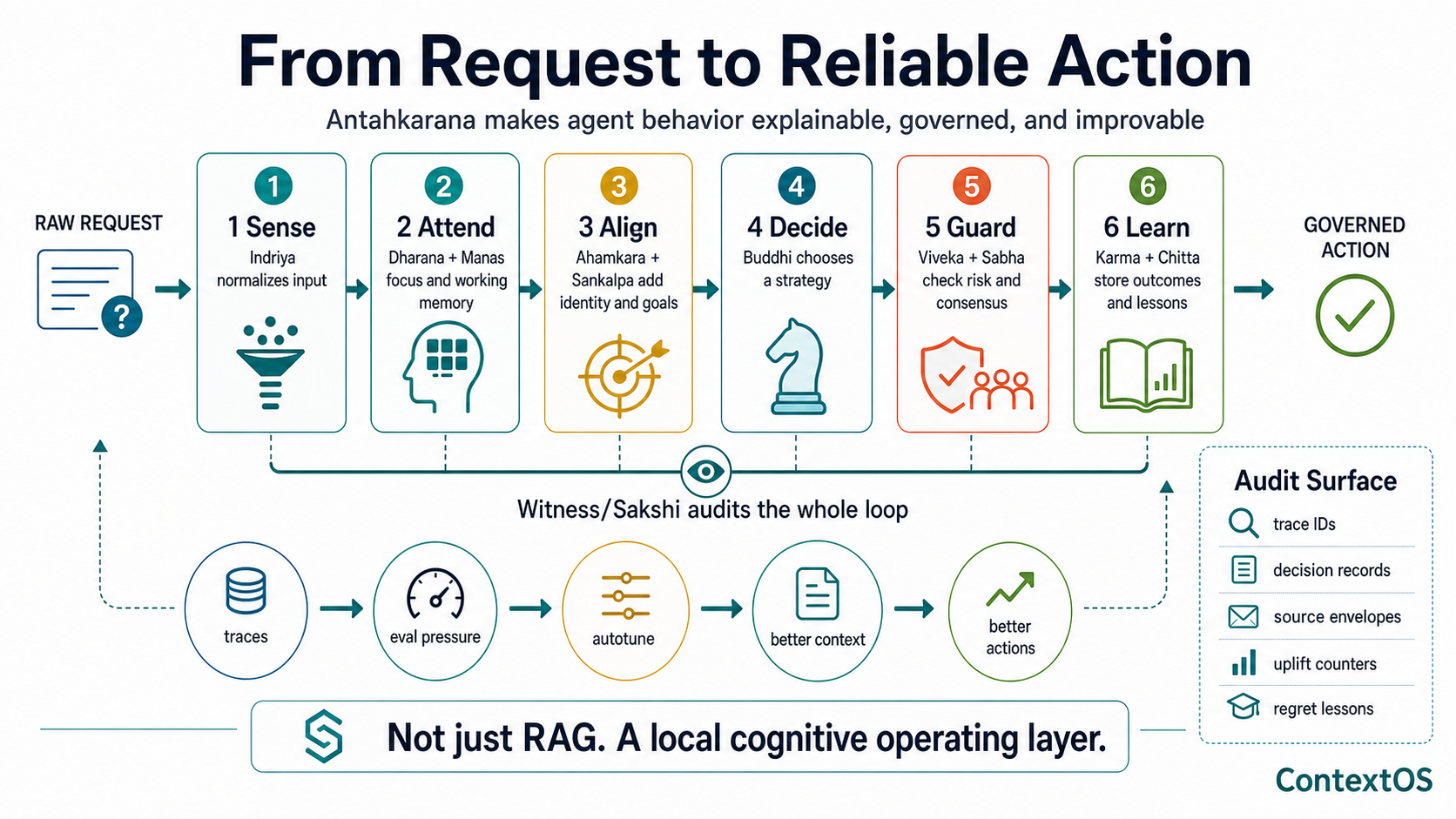
The stack turns a raw request into a governed action path, then feeds traces, eval pressure, lessons, and memory back into future context.
Each step makes a production claim:
| Step | Reliability claim |
|---|---|
| Sense | The runtime knows where input came from and can normalize it. |
| Attend | The runtime can say why something became the active focus. |
| Align | The runtime can bind the turn to identity, values, constraints, and goals. |
| Decide | The runtime can record the strategy, confidence, and alternatives. |
| Guard | The runtime can block, defer, or escalate before side effects. |
| Learn | The runtime can store outcomes and lessons without silently polluting future context. |
This is why the positioning is: not just RAG, but a local cognitive operating layer.
RAG answers the question “what evidence should the model see?” Antahkarana asks several more:
- What should the agent care about right now?
- What goal or identity makes this relevant?
- Is the answer confident enough?
- Should the proposed action be allowed?
- What did the action teach the system?
- Should that lesson become future memory?
- Is the system under pressure or behaving incoherently?
Those questions are what real operators ask after important runs.
A trace contract
The stack becomes production-grade when every layer can leave a receipt. A minimal trace does not need to expose private content. It needs to expose the decisions that shaped the run.
{
"trace_id": "run_2026_05_20_001",
"runtime_version": "antahkarana_v0.1",
"policy_version": "trust_policy_2026_05",
"model_context": {
"provider": "local_or_cloud",
"model": "selected_model",
"temperature": 0.2
},
"source_envelope": {
"kind": "support_thread",
"provenance": "local_mailbox",
"sensitivity": "customer_data",
"evidence_ids": ["doc_123", "policy_456"]
},
"working_memory_pack": {
"focus": "refund policy exception",
"salience_map": ["current_policy", "customer_tier", "prior_resolution"]
},
"identity_frame": {
"acting_as": "support_agent",
"constraints": ["no_refund_without_policy_evidence", "ask_before_external_send"]
},
"goal_alignment_score": 0.74,
"decision_record": {
"strategy": "search_more",
"confidence": 0.62,
"alternatives": ["answer_from_memory", "escalate_to_human"]
},
"policy_check": {
"status": "defer",
"reason": "missing current policy evidence"
},
"action_ledger": {
"side_effect": "none",
"result": "user asked for policy document"
},
"memory_promotion_record": {
"status": "not_promoted",
"reason": "case-specific, unreviewed"
},
"eval_record": {
"faithfulness": "not_evaluable_yet",
"evidence_coverage": "low",
"risk": "medium"
},
"reflection_report": {
"witness": "high uncertainty, low evidence coverage",
"pressure": "normal"
}
}That is a useful receipt. It tells the user why the system did not act, what evidence was missing, and where to improve the context pack.
Failure debugging table
The layer map is useful only if it helps operators debug specific failures.
| Failure mode | Layer that should catch it | Runtime artifact | Recovery action |
|---|---|---|---|
| Wrong source used | Indriya | source_envelope | Reject source, ask for trusted input. |
| Too much irrelevant context | Manas | salience_map, working_memory_pack | Prune context, reduce recall window. |
| Acting outside user or project role | Ahamkara | identity_frame | Rebind role, ask for delegation boundary. |
| Goal drift | Sankalpa | goal_alignment_score | Restate goal, narrow the active objective. |
| Overconfident answer | Buddhi | decision_record, confidence_calibration | Force search-more, synthesize alternatives, or defer. |
| Unsafe side effect | Viveka | policy_check, approval_record | Block, ask approval, or escalate. |
| Weak reasoning | Sabha | deliberation_votes | Add critic pass, request missing evidence. |
| Silent bad action | Karma | action_ledger, outcome_record | Create rollback task, record regret lesson. |
| Memory pollution | Chitta | memory_promotion_record | Mark as case-specific, do not promote. |
| Poor run quality | Witness/Sakshi | reflection_report | Lower confidence, trigger review or replay. |
| Degraded runtime state | Bhava Monitor | pressure_report | Narrow scope, slow down, recover. |
This table is the difference between a concept note and an architecture contract. If a layer cannot emit an artifact, it is just a label.
The power of the stack
1. Better context, not just more context
Manas makes attention explicit. It scores salience from urgency, novelty, relevance, recency, open-loop pressure, and goal alignment. Working memory is not a random pile of retrieved chunks. It is a bounded assembly of focus, recall hits, identity cues, and active goals.
That matters because longer prompts do not automatically create better agents. Better context comes from selection pressure. Antahkarana gives that selection pressure a home.
2. Identity-aware decisions
Ahamkara is the runtime identity layer. In engineering terms, it is where the runtime keeps roles, current themes, ambitions, values, constraints, taste, project ownership, and stakeholder context.
In software terms, Ahamkara does not mean ego or selfhood. It means the explicit role-frame under which the runtime is acting: assistant, researcher, coding agent, support agent, founder-agent, or delegated operator.
This is not personality fluff. A system that knows “I am acting as a founder,” “this project is safety-critical,” or “this user values conservative changes” can shape attention and judgment differently from a stateless assistant.
The important part is that identity becomes data the runtime can inspect, not a hidden sentence buried in a system prompt.
3. Goal pressure without tunnel vision
Sankalpa keeps active goals and alignment scores visible. That lets the runtime prefer work that advances the current mission while still allowing Viveka, Sabha, and Witness/Sakshi to catch overcommitment, risky shortcuts, or degraded reasoning.
In a production agent, goal pressure is useful only when it is bounded. Antahkarana gives the system both the goal layer and the layers that can restrain it.
4. Judgment before action
Buddhi is the judgment layer. It can choose among strategies such as direct answer, search more, or synthesize. It can calibrate confidence, detect contradictions, weigh costs and benefits, and emit a decision memo.
This is where agent behavior becomes easier to debug. If the system should have searched more but answered directly, the failure belongs to Buddhi. If context contradicted itself and the system did not synthesize carefully, the failure again has a named place.
5. Guardrails outside model text
Viveka is the discernment and approval gate. It checks policy, consent, truthfulness, source reliability, value alignment, stakeholder impact, precedent, and consequence risk depending on configuration.
The key point is that guardrails are not just “be careful” instructions. They are checks between judgment and action. When paired with Sabha, weak approvals can face dissent, historical precedent, or curator review before an effect happens.
6. Memory with receipts
Karma and Chitta separate outcome from memory.
Karma records what happened: the action, confidence, outcome, regret, lesson, feedback, and trace. Chitta decides what should be stored or recalled as memory. That separation is important because agents should not automatically convert every action into future truth.
A mature memory system needs a ledger, not just a vector database.
7. Witness reflection and pressure monitoring
Witness/Sakshi watches the loop as an audit surface. Bhava Monitor watches functional state. Together they let the system say, “the answer completed, but uncertainty was high,” or “the system is under pressure and should recover, narrow scope, or defer.”
This is the part many demos skip. Production systems do not only fail when facts are wrong. They fail when urgency, interruptions, budget pressure, low evidence, stale memory, or overconfident reasoning combine. A pressure monitor gives that condition a surface.
How it maps to ContextOS
Antahkarana is not a replacement for ContextOS. It is a cognitive architecture that fits naturally on top of the same governed-runtime primitives.
| ContextOS plane | Antahkarana contribution |
|---|---|
| Intelligence | Chitta memory, Ahamkara identity, Sankalpa goals, Indriya source signals |
| Context | Dharana focus discipline, Manas working memory, salience, and bounded recall |
| Decision | Buddhi judgment, Witness/Sakshi reflection |
| Action | Karma outcome ledger and tool-effect trace linkage |
| Trust | Viveka guardrails, Sabha consensus, Bhava pressure and recovery signals |
This is why the stack is useful for marketing and for architecture reviews. It gives non-technical buyers a simple story: “our agents do not just answer; they sense, attend, decide, guard, act, learn, and reflect.” It gives technical teams a sharper contract: “which layer owned the failure, and which artifact proves it?”
Both audiences need the same thing: understandable agent behavior.
A practical implementation slice
Do not start by implementing all twelve responsibilities as heavy services. Start with one valuable workflow and one trace format.
A useful first slice:
- Indriya normalizes the request and source.
- Dharana records focus mode and interrupt handling.
- Manas records salience and working-memory selection.
- Sankalpa attaches active-goal alignment.
- Buddhi emits strategy, confidence, and next action.
- Viveka blocks or approves the action based on evidence and policy.
- Karma records the result.
- Chitta stores only reviewed lessons or clearly scoped memories.
- Witness/Sakshi reports uncertainty and coherence at the end of the run.
That slice already gives the operator better answers than a black-box prompt loop:
trace_id: run_...
source_envelope: support_thread
focus: "refund policy exception"
active_goal: "resolve customer case without policy drift"
strategy: "search_more"
confidence: 0.62
viveka: "defer: missing current policy evidence"
karma: "no side effect"
witness: "high uncertainty, low evidence coverage"The implementation should make these artifacts queryable by trace ID, visible in evaluation, and eligible for replay. Once that is true, Antahkarana is no longer a vocabulary layer. It is a runtime contract.
Common misconceptions
| Misconception | Better reading |
|---|---|
| ”This is a canonical Vedic runtime.” | No. The traditional anchor is the four inner faculties; the stack is an engineering extension inspired by them. |
| ”This gives the machine a soul.” | No. Atma belongs to the traditional human metaphysics. The runtime has a witness-style audit surface only. |
| ”This is just a fancy prompt.” | The value is the layer contract and persisted artifacts, not the names alone. |
| ”Every layer needs an LLM call.” | Deterministic behavior should remain the core path; model enrichment can refine bounded outputs. |
| ”Memory means everything is saved.” | Karma records outcomes; Chitta consolidates selectively. Promotion rules still matter. |
| ”Guardrails live in the system prompt.” | Viveka and Sabha sit between judgment and action where policy can be tested. |
| ”Reflection is only for summaries.” | Witness/Sakshi and Bhava Monitor expose uncertainty, coherence, pressure, and recovery needs. |
The stack works when the names map to operational responsibilities. If the names become decoration, the architecture loses its value.
The takeaway
Antahkarana is compelling because it gives agentic systems a fuller loop:
sense -> attend -> align -> judge -> guard -> deliberate -> act -> learn -> remember -> reflectThat loop is more honest than pretending a single prompt can own context, policy, memory, tools, identity, goals, and quality. It gives builders something to test. It gives operators something to inspect. It gives buyers a credible story for why the agent can improve without becoming ungoverned.
Antahkarana Stack is not a mystical claim about machines. It is a Vedic-inspired engineering vocabulary for making agent behavior inspectable: what entered, what mattered, what role framed the work, what was decided, what was blocked, what happened, what was remembered, and what should improve next.
A working implementation of the Antahkarana Stack ships inside SecondBrain, an open-source local-first agent operating system. The brain/antahkarana/ modules (chitta, manas, buddhi, viveka, and more) put this layer map into running code you can inspect. If you want to improve the runtime or pressure-test the architecture, the repo is open — clone it, run the quickstart, and open an issue or PR.