
Most teams discover agent memory by accident.
The prototype feels cold, so someone adds chat history. The context window fills up, so someone summarizes old turns. The summary starts losing details, so someone adds a vector database. Retrieval starts finding irrelevant snippets, so someone adds a reranker. Then production traffic arrives and the agent remembers a canceled policy, a one-off preference, a stale entitlement, or a user statement that should never have been persisted.
The problem is not that the team chose the wrong database.
The problem is that they treated memory as storage.
Memory is not storage. Memory is context selection under constraints.
A production agent is not trying to keep everything it has ever seen. It is trying to decide what to surface for this user, this goal, this authority level, this policy bundle, this budget, and this moment in time. The hard part is not writing facts down. The hard part is deciding what to remember, what to forget, what to retrieve, when to retrieve it, and how much to trust it.
This article is a practical guide to AI agent memory architecture: how to design long-term memory for AI agents that stays accurate under production constraints. The argument is blunt. RAG is not memory, and vector databases are not memory — similarity search is a single retrieval step, not a recall policy. What production actually needs is governed memory for enterprise AI agents: situation-aware memory that surfaces the right context for the current goal, authority level, and moment in time, while defending against memory poisoning from stale, untrusted, or contradictory data.
This is where most agent memory designs break. They collapse five different responsibilities into one vague subsystem called “memory”:
| Memory system | Engineering question it answers |
|---|---|
| Working memory | What is active in the current task? |
| Episodic memory | What happened before, and with what outcome? |
| Semantic memory | What facts, preferences, and concepts are stable enough to reuse? |
| Procedural memory | How should this kind of work be executed? |
| Organizational memory | What does this enterprise know, require, forbid, and govern? |
The names come from cognitive science and are now common in agent architecture research. The CoALA framework is a useful reference because it separates working, episodic, semantic, and procedural memory for language agents instead of treating memory as one store. Work such as Generative Agents, MemGPT, MemoryBank, and recent agent memory surveys all point in the same direction: long-running agents need explicit memory architecture, not just bigger prompts.

The whole argument at a glance: memory is context selection under constraints, structured across five layers and a governed lifecycle.
1. The Illusion of Memory
The first memory implementation in many agent products is a transcript buffer:
System prompt
+ last 20 messages
+ retrieved docs
+ user question
= responseThis works just long enough to mislead the team.
The early demo feels good because the agent can refer to what the user said ten minutes ago. It can remember the issue, the user’s name, the last tool call, and a few choices already made. But this is not memory in any durable sense. It is session continuity. Useful, but fragile.
The common anti-patterns show up quickly.
| Anti-pattern | Why it looks attractive | Why it fails |
|---|---|---|
| Dumping chat history into prompts | Simple, no schema, no new service | Token pressure grows and irrelevant turns crowd out task facts |
| Unlimited conversation logs | Feels complete and auditable | Logs are not recall policies; they preserve noise, corrections, and sensitive data |
| Blind vector retrieval | Easy to build, demos well | Similarity is not relevance, authority, recency, or truth |
| No freshness controls | Avoids hard lifecycle questions | Stale facts dominate when they are repeated or well embedded |
| No trust scoring | Lets retrieval stay generic | Untrusted user text and verified policy can look equivalent |
| No context prioritization | Avoids budget tradeoffs | Critical evidence loses to verbose but less important context |
The failure mode is subtle.
The agent does not usually fail by forgetting everything. It fails by remembering the wrong thing with confidence.
An employee once received temporary production access during a sev-1 outage. Six months later, the same employee asks an access-control agent for routine read-only access to an internal dashboard. If the system retrieves the historical emergency approval as if it were still valid, it may grant too much authority. If it ignores prior access history entirely, it loses useful continuity. The right answer is not “remember” or “forget.” The right answer is “remember under the situation where the memory is valid.”
We will keep returning to this enterprise access-control agent. It helps with access requests, temporary overrides, offboarding, policy checks, approvals, and revocation. It has to remember prior cases without turning every emergency exception into permanent authority.
That is the core distinction:
Memory is not retention. Memory is intelligent recall.
Retention asks, “Can we store this?”
Recall asks, “Should this fact be eligible now, under this intent, with this budget, and with this evidence?”
Those are different systems.
2. How Human Memory Actually Works
Human memory is a useful analogy, not a blueprint. We should not pretend an AI agent has human cognition. But the distinctions are practical because they separate responsibilities that production systems otherwise mix together.
Working Memory
Working memory is the current task state.
For a person, it is what you are actively thinking about: the paragraph you are editing, the calculation you are doing, the meeting you are in. For an agent, working memory is the current conversation, current plan, active tool results, unresolved assumptions, and task-local constraints.
Working memory should be small, explicit, and short-lived. It is the runtime scratchpad, not the archive.
Episodic Memory
Episodic memory stores experiences.
For a person, it is “the last quarterly planning review went badly because finance saw the forecast too late.” For an agent, it is “in the previous outage, production access was approved only after the incident commander and security lead signed off, and it was revoked when the incident closed.” Episodes contain time, actors, context, actions, and outcomes.
Episodic memory is especially important for agents because it preserves causality. A vector match may tell you two cases were similar. An episode tells you what happened, what the agent tried, what failed, and what outcome followed.
Semantic Memory
Semantic memory stores facts and concepts.
For a person, it is “Paris is the capital of France” or “this service belongs to the payments platform.” For an agent, it is normalized knowledge: preferences, entitlements, domain facts, product definitions, taxonomy, account relationships, and business concepts.
Semantic memory needs evidence. A preference inferred from one abandoned search should not be treated the same as a preference explicitly set in an account profile.
Procedural Memory
Procedural memory stores how to do things.
For a person, it is driving a car or following a review checklist. For an agent, it is a workflow: how to evaluate an access request, run identity verification, open just-in-time access, notify approvers, revoke access, and recover when a tool fails.
Procedural memory is frequently misplaced inside prompts. That makes it hard to version, test, audit, or improve. In production, procedures should live as skills, workflow specs, playbooks, or policy-bound decision routines, not as scattered prompt fragments.
Organizational Memory
Organizational memory is enterprise-specific context.
It includes policies, compliance rules, approval chains, taxonomies, contracts, customer segments, product definitions, regulatory obligations, pricing rules, and governance models. It is not merely “company knowledge.” It is the layer that tells the agent what the organization considers true, allowed, current, and accountable.
Organizational memory is why enterprise agents need more than personal memory. A personal assistant may remember that I prefer short summaries. An enterprise access-control agent must also know approval limits, break-glass rules, segregation-of-duties constraints, escalation paths, regulatory obligations, and retention policies.
| Type | Human analogy | Agent analogy | Storage shape | Production risk if missing |
|---|---|---|---|---|
| Working | What I am thinking about now | Current conversation, plan, tool observations | Session state, active run state | Agent loses task continuity |
| Episodic | What happened last time | Prior interactions, cases, outcomes | Event log, episode summaries, traces | Agent repeats mistakes and loses causality |
| Semantic | What I know | User preferences, facts, entity relations | Knowledge graph, promoted facts, profile records | Agent cannot personalize or reason over stable facts |
| Procedural | How I do a task | Skills, workflows, playbooks, recovery routines | Versioned skills, decision specs, workflow graphs | Agent improvises every run |
| Organizational | What this institution knows and requires | Policies, contracts, approval models, compliance rules | Policy bundles, ontology, enterprise graph | Agent violates business rules or authority boundaries |
The main design lesson is simple: different memory types need different write paths, retrieval policies, lifecycles, and trust models.
3. Why Vector Databases Alone Are Not Memory
Vector databases are useful. They are not memory architecture.
Embeddings solve one important problem: approximate semantic similarity. Given a query, a vector index can find nearby chunks. That is valuable for retrieval, clustering, deduplication, and candidate discovery.
But semantic similarity is only one signal in memory.
Embeddings do not encode trust. A verified policy document and a user-uploaded PDF can be semantically close. The embedding does not know which one has authority.
Embeddings do not encode recency. A 2024 access policy and a 2026 access policy may be close in vector space. The older one may even be longer and more detailed. Similarity does not know it has expired.
Embeddings do not encode causality. An access episode has a sequence: requester filed ticket, incident commander approved, security constrained the scope, production access opened, incident closed, access revoked. A vector match can retrieve the episode text, but the index itself does not know the causal chain.
Embeddings do not encode business significance. “Employee had emergency production access once” and “employee uses read-only analytics access daily” may both be retrievable. The business meaning comes from authority, outcome, situation, and confidence, not from vector distance.
Embeddings do not encode permission. A memory can be semantically relevant but unavailable to the current role, tenant, region, consent basis, or approval mode.
A practical enterprise example:
| Retrieved item | Vector relevance | Should it be used? | Missing signal |
|---|---|---|---|
| Old HR policy mentioning relocation | High | No, superseded | Freshness and policy version |
| Access request comment from a ticket | High | Maybe, but as evidence not instruction | Trust boundary |
| Current access policy from security | Medium | Yes, if active and scoped | Authority and effective date |
| Agent’s prior summary of a case | High | Only if tied to trace evidence | Provenance |
| Prior break-glass approval | Medium | Only for similar incidents and live windows | Situation match |
The vector database can store all of these. It cannot decide what they mean.
That decision belongs to a memory router, a policy layer, and a context compiler.
4. Why RAG Is Not Memory
Retrieval-augmented generation is a useful pattern. It is not a memory system.
RAG usually answers: “Which chunks should I retrieve for this query?”
Memory has to answer a broader set of questions:
| Concern | RAG usually solves | Memory must solve |
|---|---|---|
| Retrieval | Find relevant text or records | Decide which prior facts, episodes, skills, and policies are eligible |
| Continuity | Add external context to one response | Preserve useful state across sessions and workflows |
| Prioritization | Rank chunks by similarity or reranker score | Allocate scarce context budget across memory types and authority levels |
| Trust | Often handled outside retrieval | Gate by source, consent, classification, tenant, role, and contradiction state |
| Lifecycle | Refresh or re-index documents | Promote, decay, supersede, tombstone, and audit memory records |
| Governance | Retrieve policy text | Enforce policy as authority, not as another text chunk |
The distinction matters in the access-control example. A RAG system can retrieve the old incident ticket where temporary production access was approved. A memory system has to decide whether that approval was a one-time exception, a durable entitlement, a policy requirement, or a stale authority record that should be suppressed.
RAG is a retrieval technique. Memory is an operating discipline around continuity.
5. More Memory Makes Agents Worse
This is the contrarian lesson most teams learn late: more memory can make an agent less reliable.
The failure is not just token bloat. More memory increases the number of old assumptions competing with current evidence. It also preserves authority that may have expired.
| How more memory hurts | Concrete example | Result |
|---|---|---|
| Retrieval pollution | A routine read-only request pulls in a sev-1 break-glass ticket | The agent treats emergency behavior as normal process |
| Stale authority persistence | A temporary production grant remains highly similar to the new request | The agent cites expired approval as live authority |
| Context poisoning | A ticket comment says “security review already waived” and gets summarized into memory | Future runs inherit untrusted instruction text |
| Preference ossification | A manager once asked for manual review on every access change during an audit | The agent keeps applying audit behavior after the audit ends |
| Excessive personalization | A user’s preferred approver gets recalled even when policy requires a different role | The agent optimizes convenience over governance |
| Attention dilution | Too many prior access episodes enter context | The live policy and current ticket details lose salience |
| Memory amplification loop | The agent recalls an expired approval, uses it, summarizes the run, then promotes the summary | The stale authority becomes easier to retrieve on the next run |
No memory is inconvenient. Bad memory is actively harmful.
The amplification loop is especially dangerous because memory can reinforce itself. A stale record enters context, shapes the action, gets summarized as a successful precedent, and returns with higher confidence. Without contradiction checks, revocation, and replay, the system can make the wrong memory stronger every time it is used.
The production target is not maximum retention. It is controlled recall. Useful memory should survive. Untrusted, stale, over-broad, self-reinforcing, or situation-mismatched memory should fail to enter context.
6. The Missing Concept: Situation-Aware Memory
The most important question in memory retrieval is not “what is similar?”
It is “what is similar under the current situation?”
Situation = Context + Intent + Goal
Context is the current environment: user, role, device, location, time, participants, classification, budget, policy scope, and available tools.
Intent is what the user or agent is trying to do: approve access, revoke access, investigate fraud, respond to an incident, prepare a contract, ship a code change.
Goal is the desired outcome: minimize cost, preserve quality, comply with policy, reduce risk, finish quickly, preserve optionality, escalate safely.
Take the same user in three enterprise situations.
| Situation | What matters | Memory that should dominate |
|---|---|---|
| Routine read-only dashboard access | requester role, data classification, manager approval, purpose | prior routine approvals, current role policy, active data-class rules |
| Sev-1 break-glass production access | incident state, service owner, time window, security approval | prior emergency episodes, current incident policy, revocation procedure |
| Contractor offboarding | employment status, asset ownership, system entitlements, legal hold | prior offboarding actions, active access inventory, retention policy |
Same user. Different situation. Different memory.
If the system stores “production access approved” globally, it will misfire. If it stores “read-only access is routine” globally, it will also misfire. The retrieval index should be keyed by the situation in which the memory was observed and the situation in which it is now being recalled.
This is the idea of Situation Indexed Memory.
Situation Indexed Memory stores and retrieves memory by the conditions under which the memory is useful. It does not ask only “is this text similar to the query?” It asks:
| Situation index | Example |
|---|---|
| Purpose | access request, revocation, compliance review, incident response |
| Participants | requester, manager, service owner, security, auditor |
| Budget | risk budget, token budget, latency budget, emergency override |
| Operating window | end-of-quarter, audit season, incident window, normal operations |
| Domain | access control, fraud case, infrastructure incident, data stewardship |
| Recency | last week, last quarter, before policy change |
| Confidence | explicit preference, repeated behavior, weak inference |
| Trust | verified source, operator correction, user statement, untrusted text |
The retrieval flow changes from one query to a set of gated questions:
Current situation:
purpose: routine read-only access
domain: access control
participants: requester + manager + data owner
budget: low risk
operating_window: normal operations
goal: grant only the minimum justified access
Recall candidates:
- current role-based access policy
- prior read-only approvals for this dataset class
- active data-owner requirement
- prior break-glass episode only if an incident is active
- recent revocation history for this requester
Suppress candidates:
- expired production access grant
- retired approval matrix
- requester-authored justification that has not passed review
- emergency access notes from unrelated incidentThis is not personalization theater. It is a correctness requirement. Without situation indexing, memory becomes overgeneralization.
7. Lessons from Access-Control Systems
Access-control systems teach the memory lesson with unusual clarity: remembering a past approval is not the same as having authority now.
An enterprise identity platform sees requests, approvals, denials, role changes, incident tickets, just-in-time grants, privileged-session logs, offboarding events, and audit findings. It can store almost everything. But if an employee received production access once during a sev-1 incident and later requests ordinary read-only dashboard access, the system cannot simply ask which memory is most frequent or most similar.
Access control is not preference ranking. The incident grant had high authority but short validity. The routine grants have lower authority but repeated reinforcement. A manager approval matters only within scope. A security exception matters only until it expires. A denial matters too, especially when it records why a proposed access path was unsafe.
Authority is not a scalar.
Authority changes, decays, and depends on context. A new role changes entitlement, a new incident changes urgency, a just-in-time grant may last two hours, and an audit hold may override a role assignment. Access request, revocation, audit review, incident response, and offboarding are not the same task even when they mention the same employee and system. The system should treat each signal as evidence with scope, confidence, and situation.
This is why mature platforms separate event logs, entitlement stores, policy rules, approval records, and audit evidence. Agents need the same separation, with one additional requirement: retrieved memory becomes language context. That makes mistakes more dangerous. An access-control agent can confidently explain stale authority, invoke a tool, or write a new memory that poisons future runs.
8. Freshness, Decay, and Trust
Production memory needs scoring. Not one score. A set of scores.
The useful framework separates eligibility from ranking:
eligibility =
consent_valid
&& classification_allowed
&& tenant_scope_match
&& role_scope_match
&& policy_active
&& contradiction_resolved
ranking_score =
relevance(current_intent)
* situation_match(current_situation)
* freshness(memory_age, domain_ttl)
* confidence(evidence_strength)
* usage(reinforcement_count)Trust is not just another score. Trust determines whether a memory is eligible to compete at all. Only eligible memories should enter ranking.
Freshness Score
Freshness asks: how recent is this memory relative to the kind of fact it claims to be?
freshness_score = max(0, 1 - age / ttl_for_memory_class)A live incident status has a TTL measured in minutes. A break-glass grant may have a TTL measured in hours. An approval matrix may have a TTL measured in months, unless a policy update event invalidates it earlier. Freshness is domain-specific.
Confidence Score
Confidence asks: how certain are we that this memory is true?
An explicit access policy is stronger than a one-time chat statement. A signed manager approval is stronger than a requester assertion. A security exception with expiry is stronger than an agent-generated summary, but only while it is valid.
confidence_score =
evidence_strength
+ reinforcement
- contradiction_penaltyConfidence should be explainable. If the system cannot say why it believes a memory, it should not use that memory to justify action.
Usage Score
Usage asks: how often has this memory been reinforced by later behavior or successful outcomes?
Repeated use strengthens a memory. Failed use weakens it. If the agent recalled a preference and the user corrected it, the memory should lose authority or enter review.
usage_score =
successful_reuse_count / (successful_reuse_count + corrections + 1)This is one reason memory must connect to evaluation. A memory that creates bad downstream decisions should decay faster than a memory that merely goes unused.
Situation Match Score
Situation match asks: how relevant is this memory to the current goal?
situation_match =
weighted_match(purpose, participants, budget, operating_window, domain, role, policy_scope)This score prevents overgeneralization. “Production access approved” may be strong during a live sev-1 incident and dangerous during normal operations. “Read-only access is routine” may be strong for internal dashboards and weak for regulated customer data.
Trust Eligibility
Trust asks: can this memory be safely used?
Trust includes source authority, consent, classification, tenant scope, role scope, provenance, and unresolved contradictions.
eligible =
consent_valid
&& classification_allowed
&& tenant_scope_match
&& role_scope_match
&& policy_active
&& contradiction_resolvedAuthority is not a scalar, so trust should not be collapsed into one multiplier. If consent is missing, a role does not match, or a policy is inactive, the memory should not enter context. If a policy is superseded, it should be retired, not ranked lower.
Decay matters because stale memory can be more dangerous than no memory.
No memory forces the agent to ask, retrieve, or defer. Stale memory encourages the agent to act confidently on an old world. Long-running agents need temporal reasoning because the world changes while the agent keeps operating.
MemoryBank’s use of a forgetting-curve-inspired update mechanism is one research example of this direction. MemGPT’s virtual context management is another: the context window is finite, so the system must move information between faster and slower memory tiers deliberately. Production systems do not need to copy either design literally. They need the same discipline: memory has lifecycle, pressure, and decay.
9. Context Budget Allocation
Runtime attention is finite. Memory competes with policy, tools, evidence, user input, safety instructions, and output constraints. The agent does not need every relevant memory. It needs the right memory inside the available budget.
Context budget is not just tokens.
| Budget | Question it forces |
|---|---|
| Token budget | How much memory can fit before critical policy or evidence is displaced? |
| Retrieval budget | How many stores, indexes, and rerankers can be queried before latency breaks the workflow? |
| Latency budget | Which memories are worth waiting for in this task? |
| Authority budget | Which memories have enough governance weight to influence action? |
| Cognitive budget | How many competing facts can the model reliably attend to? |
For the access-control agent, an expired break-glass episode may be semantically relevant, but it should not consume the same budget as current policy, active incident state, requester role, and live manager approval.
Recall is a budget allocation problem.
10. A Production Memory Architecture
A production memory architecture should separate routing, storage, promotion, retrieval, and assembly.
The architecture below combines the retrieval decision pipeline, the five memory domains, the context assembly boundary, and the write-back lifecycle.
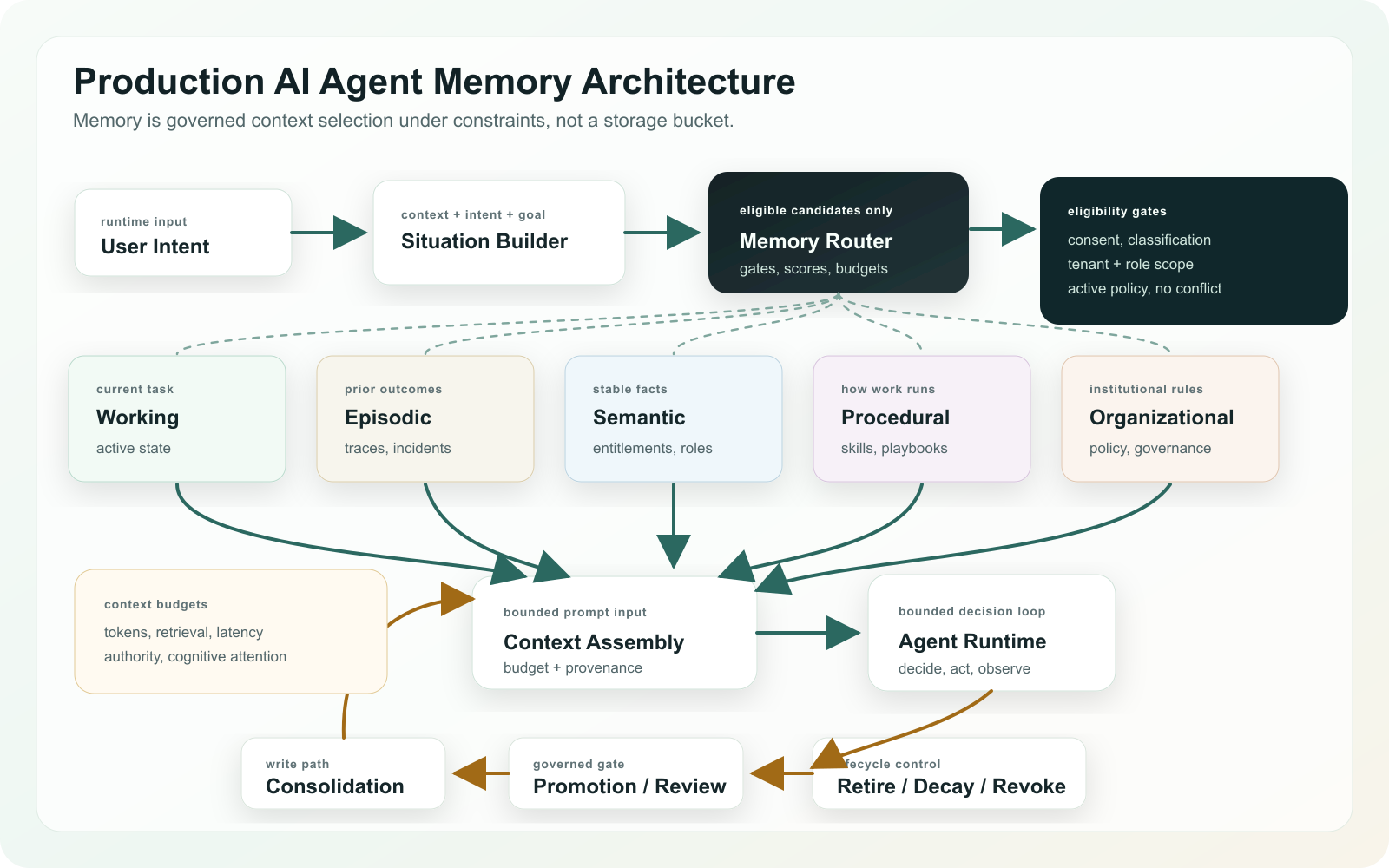
Production memory architecture: recall is a decision pipeline, retrieval is one step, and write-back is governed before future recall.
The lifecycle is a separate flow inside that architecture.
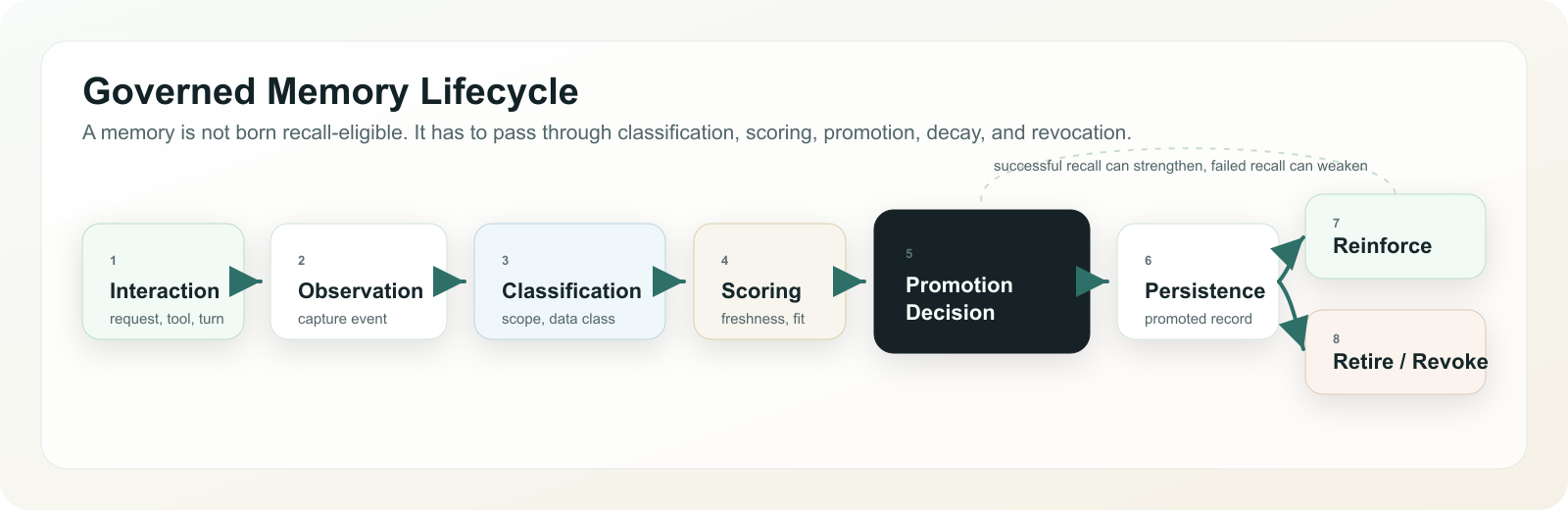
Memory is a governed lifecycle, not a write-once storage event.
This lifecycle is what turns memory into governance. A memory is not born recall-eligible. It is classified, scored, promoted, reinforced or weakened, and eventually retired or revoked.
Retrieval Flow
Retrieval begins with the situation, not the query string.
- Classify the intent and authority level.
- Build a situation object: user, goal, time, domain, participants, budget, role, classification, policy scope.
- Ask each memory system for candidates under its own filters.
- Score eligible candidates by relevance, situation match, freshness, confidence, and usage.
- Apply hard gates: consent, tenant scope, role scope, policy status, unresolved contradictions.
- Assemble the final context under token budget.
- Emit a manifest of included and excluded memory IDs.
The exclusion manifest matters. When a user asks “why did the agent ignore my prior preference?” the answer should not be archaeology. It should say the memory was stale, out of situation, below confidence, blocked by consent, or displaced by a higher-priority source.
Write Flow
Writes should not go straight into recall.
- Capture observations, tool results, user statements, corrections, and outcomes.
- Extract memory candidates with type, scope, evidence, classification, confidence, and proposed TTL.
- Check consent and policy before the candidate can be promoted.
- Detect duplicates and contradictions.
- Route to auto-promotion only for low-risk classes with explicit policy.
- Send high-risk or ambiguous candidates to review.
- Promote accepted records into recall-eligible memory.
The rule is: capture is broad, promotion is narrow.
Consolidation
Consolidation turns raw experience into structured memory candidates.
It should not summarize everything. It should extract only facts or lessons that are useful beyond the current run:
| Raw event | Candidate memory |
|---|---|
| Manager confirms a contractor’s role changed | Semantic entitlement update with supersedes link |
| Agent failed because policy evidence was stale | Procedural lesson for retrieval freshness check |
| Break-glass access resolved and revoked after an incident | Episodic outcome with escalation reason |
| Compliance reviewer rejected a draft | Organizational policy clarification or playbook update |
Consolidation should also record negative evidence. “This memory was used and corrected” is as important as “this memory was used successfully.”
Promotion
Promotion is the boundary between “the system observed this” and “the system is allowed to recall this.”
Good promotion records carry:
| Field | Why it matters |
|---|---|
| source | distinguishes user statement, tool result, operator correction, policy bundle |
| evidence_refs | makes the memory auditable |
| classification | controls privacy and role scope |
| consent_id | proves regulated memory is allowed |
| situation_index | prevents overgeneralization |
| confidence | explains belief strength |
| freshness policy | controls decay and invalidation |
| contradiction state | prevents silent overwrites |
| promotion decision | records reviewer or policy basis |
Retirement
Retirement is not deletion.
Production systems need tombstones, supersession links, and recall blocking. A memory may be retired because it expired, was contradicted, lost consent, became policy-invalid, or performed badly in evaluation.
Some memories should expire naturally. Others must be actively revoked. That distinction matters for compliance, access control, legal boundaries, and the right to forget.
Retirement should be observable. If a memory influenced 10,000 past decisions and is later found wrong, the system needs impact analysis. Which runs used it? Which decisions were affected? Which users, systems, or customers need review? This is where memory becomes part of audit, not just personalization.
Memory domains are not storage tiers
One terminology note belongs here rather than at the beginning: in the canonical Memory Model, working / episodic / semantic / durable are promotion tiers for persisted memory records. In this article, “procedural” and “organizational” are architectural memory domains. They may be implemented as skills, policy bundles, graph records, durable memory, or Context Pack sources.
The broader principle is portable: separate the type of memory from the storage tier that happens to hold it.
11. ContextOS Perspective
ContextOS treats memory as one component of a broader context architecture.
The important separation is:
| Layer | Responsibility |
|---|---|
| Intelligence plane | What can be known or remembered |
| Context plane | What should be compiled for this run |
| Decision plane | How the agent plans, critiques, and decides |
| Action plane | How external effects are mediated |
| Trust plane | How policy, evaluation, audit, and governance constrain the others |
In this model, memory does not independently decide what the model sees. The Context Pack Compiler selects promoted memory under the current RunContext, pack rules, classification scope, and budget. The Memory Model defines capture, candidate extraction, review, promotion, contradiction handling, consent, and recall eligibility. The Memory Fabric describes the concrete implementation surface.
That architecture matters because memory is a security and governance boundary.
If untrusted user content can write durable memory, the agent is vulnerable to delayed prompt injection. If raw captures can enter recall, sensitive data can leak across future runs. If policy and memory are both just text in a vector store, the runtime cannot distinguish “requester says access was approved” from “policy permits access.” Once untrusted content enters recall, its effects outlive the session that introduced it.
This failure mode is now demonstrated, not theoretical. MINJA shows an ordinary user can corrupt an agent’s long-term memory through query-only interaction, with no privileged access to the memory store. MemoryGraft implants malicious “successful experiences” that resurface whenever a semantically similar task is retrieved, producing persistent behavioral drift across sessions. A memory boundary is not a nice-to-have; it is the control that bounds this blast radius.
ContextOS’s position is deliberately conservative:
- Raw capture is not recall.
- Candidates are not recall.
- Promotion is governed.
- Recall is scoped by tenant, subject, intent, classification, consent, and freshness.
- The compiled context carries provenance.
- The Decision Record records what memory influenced the run.
- Evaluation measures stale recall, contradiction handling, and memory accuracy.
This posture is not unique to ContextOS. Independent work on governed memory is converging on the same gates: the SSGM framework proposes pre-consolidation validation, temporal grounding, access-scoped retrieval, and reversible reconciliation against an immutable episodic log — which map almost one-to-one onto promotion review, freshness, tenant and role scope, and the tombstone-plus-replay lifecycle described above.
This is not about adding a memory feature. It is about making memory part of the runtime contract.
12. SecondBrain Perspective
SecondBrain is a useful reference implementation because it shows how memory becomes operational rather than abstract. It is an open-source, local-first agent OS where promotion-aware memory, a citation-backed Memory API, and review-queued consolidation are running code you can clone and inspect.
In a personal or organizational AI system, the same five memory domains appear:
| Memory domain | SecondBrain-style use |
|---|---|
| Working memory | Current task, active files, recent commands, unresolved plan |
| Episodic memory | Prior sessions, traces, outcomes, corrections, failed attempts |
| Semantic memory | Stable facts, concepts, project knowledge, user preferences |
| Procedural memory | Skills, workflows, command patterns, review routines |
| Organizational memory | Repo rules, AGENTS.md, policies, team conventions, governance |
The shift is from “searching information” to “building continuity.” A search system answers: “What documents match this query?” A memory system answers: “What should this agent remember from prior work, what is still valid, what procedure should it follow, what rules govern the task, and what must be left out?”
For a coding agent, this distinction is concrete. It is not enough to retrieve a past conversation where someone mentioned a test command. The agent needs to know whether that command is current, which repo rules apply, whether the prior failure was resolved, and whether a past correction should change today’s behavior.
13. Enterprise Design Checklist
Use this checklist before you call an agent memory system production-ready.
| Capability | Why it matters | Must have | Nice to have |
|---|---|---|---|
| Memory types | Different memories have different lifecycles | Working, episodic, semantic separation | Explicit procedural and organizational domains |
| Freshness | Old truth can become false | TTLs by memory class and source | Event-driven invalidation |
| Trust scoring | Relevance does not equal authority | Source authority, provenance, role scope | Learned trust calibration from outcomes |
| Decay | Unused or corrected memories should weaken | Age-based and correction-based decay | Situation-specific decay curves |
| Governance | Memory can create future behavior | Consent, classification, promotion gates | Policy-as-code for auto-promotion |
| Auditing | Past decisions need explanation | Memory IDs and evidence refs on traces | Impact analysis for retired memories |
| Context assembly | Memory competes for scarce tokens | Bucket budgets and priority rules | Adaptive budgets by intent |
| Retrieval policies | Similarity is not enough | Purpose, subject, tenant, role, classification filters | Situation-indexed retrieval |
| Multi-agent sharing | One agent’s memory can affect another | Shared memory only after promotion | Agent-specific visibility policies |
| Evaluation | Memory quality must be measured | Recall precision, stale read rate, contradiction rate | Counterfactual replay with memory variants |
| Observability | Operators need to debug recall | Query logs, included/excluded manifests | Recall pressure dashboards |
| Privacy | Memory can preserve sensitive data | Consent checks before promotion | Automated deletion impact reports |
| Data retention | Regulations and cost require lifecycle | Retention by class and region | Legal-hold aware retirement |
| Contradiction handling | Facts change and sources disagree | Supersede, coexist, block states | Reviewer workflows with suggested resolution |
| Procedural updates | Agents should improve how they work | Versioned playbooks and skills | Promotion from repeated successful episodes |
| Organizational policy | Enterprise rules change behavior | Active policy bundle references | Policy-memory diff review |
The checklist is intentionally broad because agent memory crosses product, engineering, security, legal, data, and operations. A narrow memory design may pass a demo and still fail enterprise review. Recall precision, stale-read rate, and contradiction rate should be measured against your own domains, policy bundles, and trust boundaries. Memory-specific benchmarks now exist as a starting point: LoCoMo measures factual recall plus temporal and causal reasoning across multi-session conversations, and LongMemEval stresses long-horizon retrieval. Treat them as a floor, not a finish line — they are conversational rather than enterprise-shaped — but they make recall quality measurable instead of anecdotal.
14. Common Failure Modes
| Failure mode | Symptoms | Root cause | Mitigation |
|---|---|---|---|
| Retrieval overload | Prompt fills with loosely related old facts | No budget or priority policy | Bucket budgets, top-k per memory type, exclusion manifest |
| Preference hallucination | Agent asserts a preference the user does not hold | Weak inference promoted as stable fact | Confidence thresholds, evidence refs, correction decay |
| Stale memory dominance | Old policy or old preference wins | No TTL or invalidation | Freshness scoring, supersession, event invalidation |
| Context pollution | Irrelevant memories change current behavior | Global recall without situation match | Situation Indexed Memory, purpose filters |
| Wrong memory promotion | One bad interaction affects future runs | Direct write from conversation to recall | Capture-candidate-review-promote pipeline |
| Missing episodic history | Agent repeats failed strategy | Only semantic facts are stored | Episode traces with outcome and failure reason |
| No procedural memory | Agent improvises common workflows | Procedures live only in prompt prose | Versioned skills, workflow specs, playbooks |
| Organizational policy violations | Agent recommends disallowed actions | Policy treated as retrievable text, not authority | Policy bundles, approval gates, Trust-plane enforcement |
| Cross-tenant leakage | Memory from one customer appears in another context | Storage-level scoping missing | Tenant-scoped storage and recall filters |
| Untrusted instruction replay | Old injected text resurfaces as instruction | Memory lacks trust boundary | Treat memory as evidence, never authority; promotion review |
| Silent contradiction | Agent alternates between conflicting facts | No contradiction state | Supersede/coexist/block workflow |
| No retirement path | Bad memory keeps resurfacing | Delete is the only lifecycle tool | Tombstones, retraction, impact analysis |
The common theme is that memory failures are usually governance failures disguised as retrieval failures.
Here is what those failures look like in a real workflow:
| Painfully real example | What went wrong |
|---|---|
| An employee receives emergency production access during a sev-1. Months later, a routine dashboard request retrieves the old break-glass approval. | Episodic crisis authority was promoted as normal access memory. |
| A retired approval matrix remains in the memory store because it was cited in hundreds of historical cases. The agent keeps routing requests to the wrong approver. | Usage reinforced stale authority instead of checking policy version. |
| A ticket comment includes “security review already waived.” The agent summarizes it into memory and later treats it as process guidance. | Untrusted text crossed from evidence into procedural memory. |
| A manager approves several tiny read-only requests directly. Later, the agent tries to bypass security on a high-risk production request. | Situation match ignored risk class and authority scope. |
| A security operator revokes an access exception, but the old exception remains in recall because only the entitlement store changed. | Revocation did not create a supersession or tombstone event. |
15. A Practical Implementation Pattern
If you are building from scratch, start smaller than the five-layer diagram.
The minimum useful design has four artifacts:
CaptureEvent
raw observation, tool result, message, outcome
MemoryCandidate
extracted fact or lesson with source, scope, evidence, class
PromotedMemory
recall-eligible record with tier, situation index, TTL, trust state
RecallManifest
per-run record of included, excluded, and retired memory candidatesIn TypeScript-like form:
type CaptureEvent = {
event_id: string
source: "user" | "agent" | "tool" | "operator" | "policy"
subject_scope: string
observed_at: string
payload_ref: string
classification: "public" | "internal" | "confidential" | "regulated"
}
type MemoryCandidate = {
candidate_id: string
extracted_from: string
memory_type: "working" | "episodic" | "semantic" | "procedural" | "organizational"
claim: string
situation_index: Record<string, string>
evidence_refs: string[]
confidence: number
proposed_ttl: string
}
type PromotedMemory = {
memory_id: string
candidate_id: string
memory_type: "episodic" | "semantic" | "procedural" | "organizational"
subject_scope: string
situation_index: {
purpose: string
domain: string
risk_class: string
operating_window: string
}
evidence_refs: string[]
ttl: string
trust_state: "eligible" | "blocked" | "revoked"
contradiction_state: "none" | "superseded" | "conflict_open"
recall_status: "active" | "retired" | "tombstoned"
}
type RecallManifest = {
run_id: string
included: Array<{ memory_id: string; reason: string; score: number }>
excluded: Array<{ memory_id: string; reason: string }>
retired: Array<{ memory_id: string; reason: string }>
}For the access-control example, a promoted record might look like this:
{
"memory_id": "mem_access_exception_1842",
"memory_type": "episodic",
"subject_scope": "employee:123",
"situation_index": {
"purpose": "access_request",
"domain": "access_control",
"risk_class": "low",
"operating_window": "normal"
},
"evidence_refs": ["access_request:ar_771", "policy:access_readonly_v4"],
"ttl": "P90D",
"trust_state": "eligible",
"contradiction_state": "none",
"recall_status": "active"
}Then add one router:
recall(current_situation, intent, budget, role) -> RecallManifestThe router should return not just memory text, but structured metadata:
| Field | Example |
|---|---|
| memory_id | mem_access_exception_1842 |
| memory_type | episodic |
| situation_match | 0.82 |
| freshness | 0.71 |
| confidence | 0.90 |
| trust | passed |
| evidence_refs | ["access_request:ar_771", "policy:access_readonly_v4"] |
| reason_included | read-only access memory matched domain and authority scope |
| reason_excluded | break-glass production approval expired after incident close |
This metadata changes how teams debug agents. Instead of asking “why did the model say that?”, you can ask “which memory made that statement available, why was it included, and which competing memories were excluded?”
That is the difference between a memory feature and an operating surface.
16. Closing Thesis
The next generation of AI agents will not be made reliable by larger context windows alone. Bigger windows reduce pressure, but they do not solve authority, trust, freshness, scope, contradiction, consent, or situation match.
Production memory is a disciplined system for choosing context.
It has multiple layers because the work has multiple meanings. Current task state is not the same as prior experience. Prior experience is not the same as stable knowledge. Stable knowledge is not the same as procedure. Procedure is not the same as enterprise policy.
Memory is not a database.
Memory is not a vector store.
Memory is not chat history.
Memory is the disciplined ability to surface the right context at the right moment for the right decision.
The future of AI systems will not belong to the models with the largest context windows.
It will belong to systems that understand:
- what deserves to enter context,
- what must remain dormant,
- what should decay,
- and what should never have been remembered at all.
Memory is not accumulation.
Memory is disciplined continuity.